语音克隆
无 tokenizer 的开源 TTS 模型,支持 30 语言、声音设计与语音克隆
VoxCPM2: 无需分词器的多语音生成、创意声音设计与逼真人声克隆TTS系统
English | 中文
VoxCPM 是一种无需分词器的文本转语音系统,通过端到端扩散自回归架构直接生成连续语音表示,绕过离散分词,实现高度自然且富有表现力的合成。
VoxCPM2 是最新主要版本——一个在超过200万小时多语言语音数据上训练的 2B 参数模型,现支持30种语言、声音设计、可控语音克隆和 48kHz 录音室品质音频输出。基于 MiniCPM-4 骨干网络构建。
✨ 亮点
- 🌍 30种语言多语言支持 — 直接输入任意30种支持语言的文本即可合成,无需语言标签
- 🎨 声音设计 — 仅凭自然语言描述即可创建全新声音(性别、年龄、音调、情感、语速……),无需参考音频
- 🎛️ 可控克隆 — 从短参考片段克隆任意声音,并可选择风格引导来控制情感、语速和表现力,同时保留原始音色
- 🎙️ 终极克隆 — 复现每一个声音细节:提供参考音频及其文本,模型从参考处无缝继续,忠实保留所有声音细节——音色、节奏、情感和风格(与 VoxCPM1.5 相同)
- 🔊 48kHz 高品质音频 — 接受16kHz参考音频,通过 AudioVAE V2 的非对称编码/解码设计直接输出48kHz录音室品质音频,内置超分辨率——无需外部升采样器
- 🧠 上下文感知合成 — 自动从文本内容推断合适的韵律和表现力
- ⚡ 实时流式合成 — 在 NVIDIA RTX 4090 上 RTF 低至约0.3,经 Nano-vLLM 或 vLLM-Omni 加速后约0.13——官方为 VoxCPM2 提供的 vLLM 全模态服务,支持 PagedAttention 和兼容 OpenAI 的 API
- 📜 完全开源 & 商业可用 — 权重和代码以 Apache-2.0 许可证发布,可免费商用
🌍 支持的语言(30种)
阿拉伯语、缅甸语、中文、丹麦语、荷兰语、英语、芬兰语、法语、德语、希腊语、希伯来语、印地语、印尼语、意大利语、日语、高棉语、韩语、老挝语、马来语、挪威语、波兰语、葡萄牙语、俄语、西班牙语、斯瓦希里语、瑞典语、他加禄语、泰语、土耳其语、越南语
中文方言:四川话、粤语、吴语、东北话、河南话、陕西话、山东话、天津话、闽南话
新闻
- [2026.04] 🔥 我们发布 VoxCPM2 — 2B参数,30种语言,声音设计与可控语音克隆,48kHz音频输出!权重 | 文档 | 演示 | 技术报告
- [2025.12] 🎉 开源 VoxCPM1.5 权重 ,支持SFT与LoRA微调。(🏆 GitHub 趋势榜 #1)
- [2025.09] 🔥 发布 VoxCPM 技术报告。
- [2025.09] 🎉 开源 VoxCPM-0.5B 权重 (🏆 HuggingFace 趋势榜 #1)
目录
🚀 快速开始
安装
pip install voxcpm要求: Python ≥ 3.10 (<3.13),PyTorch ≥ 2.5.0,CUDA ≥ 12.0。详见 快速开始文档。
Python API
🗣️ 文本转语音
from voxcpm import VoxCPM
import soundfile as sf
model = VoxCPM.from_pretrained(
"openbmb/VoxCPM2",
load_denoiser=False,
)
wav = model.generate(
text="VoxCPM2 是当前推荐用于逼真多语言语音合成的版本。",
cfg_value=2.0,
inference_timesteps=10,
)
sf.write("demo.wav", wav, model.tts_model.sample_rate)
print("已保存:demo.wav")如果你更喜欢先从 ModelScope 下载,可以使用:
pip install modelscopefrom modelscope import snapshot_download
snapshot_download("OpenBMB/VoxCPM2", local_dir='./pretrained_models/VoxCPM2') # 指定本地目录保存模型
from voxcpm import VoxCPM
import soundfile as sf
model = VoxCPM.from_pretrained("./pretrained_models/VoxCPM2", load_denoiser=False)
wav = model.generate(
text="VoxCPM2 是当前推荐用于逼真多语言语音合成的版本。",
cfg_value=2.0,
inference_timesteps=10,
)
sf.write("demo.wav", wav, model.tts_model.sample_rate)🎨 语音设计
通过自然语言描述创建语音,无需参考音频。格式: 将描述放在 text 开头的括号内(例如 "(your voice description)The text to synthesize."):
wav = model.generate(
text="(A young woman, gentle and sweet voice)Hello, welcome to VoxCPM2!",
cfg_value=2.0,
inference_timesteps=10,
)
sf.write("voice_design.wav", wav, model.tts_model.sample_rate)🎛️ 可控语音克隆
上传参考音频。模型会克隆音色,同时你仍可使用控制指令调整语速、情感或风格。
wav = model.generate(
text="This is a cloned voice generated by VoxCPM2.",
reference_wav_path="path/to/voice.wav",
)
sf.write("clone.wav", wav, model.tts_model.sample_rate)
wav = model.generate(
text="(slightly faster, cheerful tone)This is a cloned voice with style control.",
reference_wav_path="path/to/voice.wav",
cfg_value=2.0,
inference_timesteps=10,
)
sf.write("controllable_clone.wav", wav, model.tts_model.sample_rate)🎙️ 极致克隆
同时提供参考音频及其精确转录文本,基于音频续接的克隆能重现每一个发音细节。为获得最大克隆相似度,将同一个参考音频同时传入 reference_wav_path 和 prompt_wav_path,如下所示:
wav = model.generate(
text="This is an ultimate cloning demonstration using VoxCPM2.",
prompt_wav_path="path/to/voice.wav",
prompt_text="The transcript of the reference audio.",
reference_wav_path="path/to/voice.wav", # optional, for better simliarity
)
sf.write("hifi_clone.wav", wav, model.tts_model.sample_rate)🔄 流式 API
import numpy as np
chunks = []
for chunk in model.generate_streaming(
text="Streaming text to speech is easy with VoxCPM!",
):
chunks.append(chunk)
wav = np.concatenate(chunks)
sf.write("streaming.wav", wav, model.tts_model.sample_rate)CLI 使用
# Voice design (no reference audio needed)
voxcpm design \
--text "VoxCPM2 brings studio-quality multilingual speech synthesis." \
--output out.wav
# Controllable voice cloning with style control
voxcpm design \
--text "VoxCPM2 brings studio-quality multilingual speech synthesis." \
--control "Young female voice, warm and gentle, slightly smiling" \
--output out.wav
# Voice cloning (reference audio)
voxcpm clone \
--text "This is a voice cloning demo." \
--reference-audio path/to/voice.wav \
--output out.wav
# Ultimate cloning (prompt audio + transcript)
voxcpm clone \
--text "This is a voice cloning demo." \
--prompt-audio path/to/voice.wav \
--prompt-text "reference transcript" \
--reference-audio path/to/voice.wav \ # optional, for better simliarity
--output out.wav
# Batch processing
voxcpm batch --input examples/input.txt --output-dir outs
# Help
voxcpm --helpWeb 演示
python app.py --port 8808 # then open in browser: http://localhost:8808使用 --device 选择运行设备:
python app.py --device auto支持的值有 auto、cpu、mps、cuda 和 cuda:N。在 Apple Silicon Mac 上,auto 会在可用时使用 MPS。
🚢 生产部署(Nano-vLLM)
为高吞吐服务,推荐使用 Nano-vLLM-VoxCPM ——一个基于 Nano-vLLM 的专用推理引擎,支持并发请求与异步 API。
pip install nano-vllm-voxcpmfrom nanovllm_voxcpm import VoxCPM
import numpy as np, soundfile as sf
server = VoxCPM.from_pretrained(model="/path/to/VoxCPM", devices=[0])
chunks = list(server.generate(target_text="Hello from VoxCPM!"))
sf.write("out.wav", np.concatenate(chunks), 48000)
server.stop()在 NVIDIA RTX 4090 上 RTF 低至 ~0.13(标准 PyTorch 实现约为 ~0.3),支持批处理并发请求和 FastAPI HTTP 服务器。部署细节请参阅 Nano-vLLM-VoxCPM 仓库。
🏭 生产服务(vLLM-Omni)
对于多租户生产部署,请使用 vLLM-Omni ——vLLM 官方项目的多模态扩展,原生支持 VoxCPM2。它提供了 PagedAttention KV 缓存、连续批处理,以及即开即用的 OpenAI 兼容 /v1/audio/speech 端点。
# Install from source (latest main — vllm-omni is rapidly evolving)
uv pip install vllm==0.19.0 --torch-backend=auto
git clone https://github.com/vllm-project/vllm-omni.git && cd vllm-omni
uv pip install -e .其他平台(ROCm、XPU、MUSA、NPU)及 Docker 镜像的安装请参阅 vLLM-Omni 安装指南。
# Launch an OpenAI-compatible TTS server (--omni enables omni-modal serving)
vllm serve openbmb/VoxCPM2 --omni --port 8000
# Call it from any OpenAI client
curl http://localhost:8000/v1/audio/speech \
-H "Content-Type: application/json" \
-d '{"model":"openbmb/VoxCPM2","input":"Hello from VoxCPM2 on vLLM-Omni!","voice":"default"}' \
--output out.wav基于上游 vLLM 调度器,内置批处理并发请求、流式块传输和多 GPU 部署。完整部署方案请参阅 VoxCPM2 示例。
📦 模型与版本
| VoxCPM2 | VoxCPM1.5 | VoxCPM-0.5B | |
|---|---|---|---|
| 状态 | 🟢 最新 | 稳定 | 旧版 |
| 骨干参数 | 2B | 0.6B | 0.5B |
| 音频采样率 | 48kHz | 44.1kHz | 16kHz |
| LM Token 速率 | 6.25Hz | 6.25Hz | 12.5Hz |
| 语言 | 30 | 2(zh, en) | 2(zh, en) |
| 克隆模式 | 独立参考与续接 | 仅续接 | 仅续接 |
| 语音设计 | ✅ | — | — |
| 可控语音克隆 | ✅ | — | — |
| SFT / LoRA | ✅ | ✅ | ✅ |
| RTF(RTX 4090) | ~0.30 | ~0.15 | ~0.17 |
| Nano-VLLM 上的 RTF(RTX 4090) | ~0.13 | ~0.08 | ~0.10 |
| 显存 | ~8 GB | ~6 GB | ~5 GB |
| 权重 | 🤗 HF / MS | 🤗 HF / MS | 🤗 HF / MS |
| 技术报告 | arXiv | — | arXiv ICLR 2026 |
| 演示页面 | 音频样例 | — | 音频样例 |
VoxCPM2 基于免分词器的扩散自回归范式构建。该模型完全在 AudioVAE V2 的潜在空间中运行,遵循四阶段流水线:LocEnc → TSLM → RALM → LocDiT,实现丰富的表现力和 48kHz 原生音频输出。
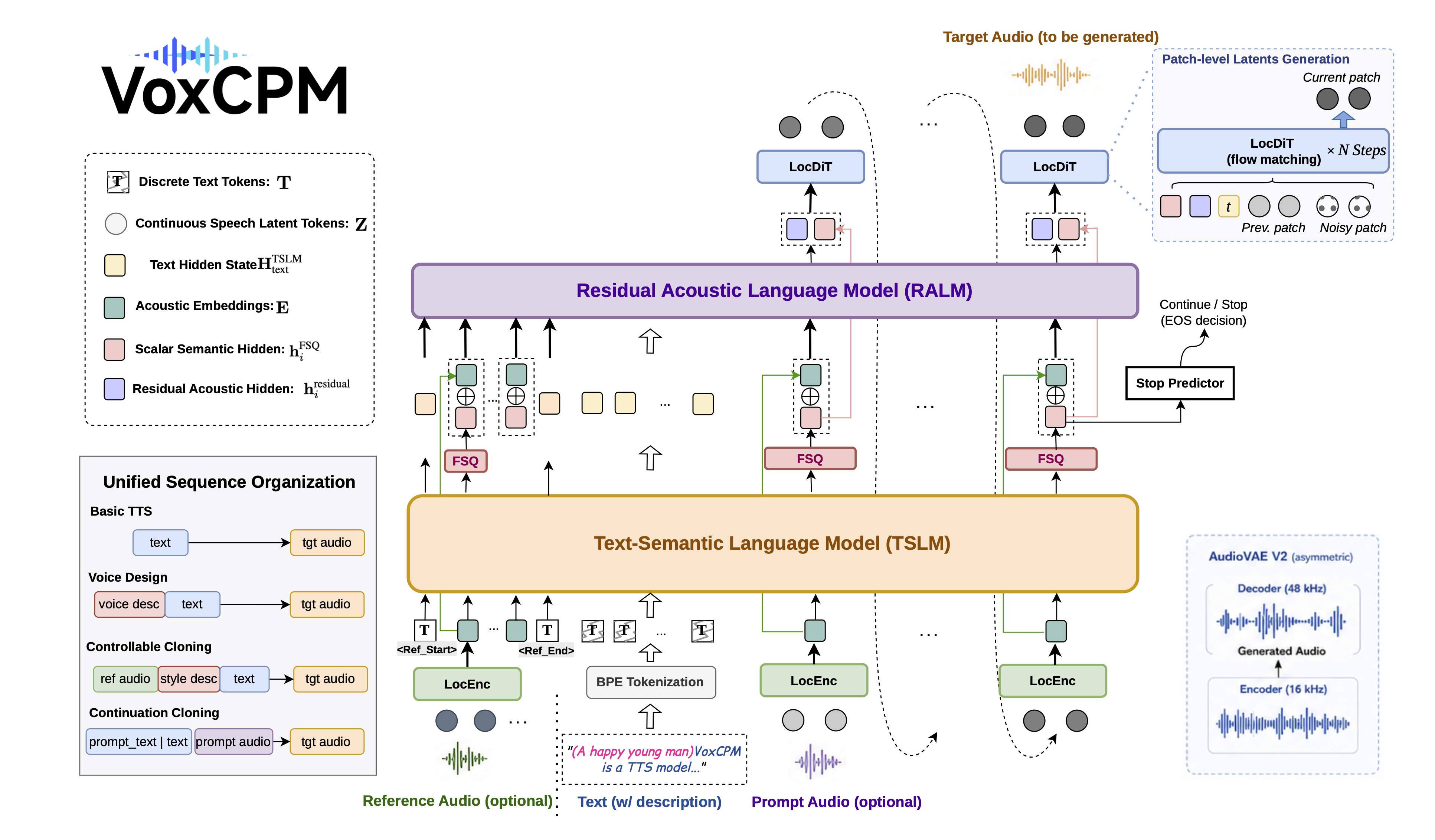
完整的架构详情、VoxCPM2 特定升级以及模型对比表,请参阅架构设计。
📊 性能
VoxCPM2 在公开的零样本和可控 TTS 基准测试中达到最先进或可比的水平。
Seed-TTS-eval
Seed-TTS-eval 的 WER(⬇) 和 SIM(⬆) 结果(点击展开)
| 模型 | 参数量 | 开源 | test-EN | test-ZH | test-Hard | |||
|---|---|---|---|---|---|---|---|---|
| WER/%⬇ | SIM/%⬆ | CER/%⬇ | SIM/%⬆ | CER/%⬇ | SIM/%⬆ | |||
| MegaTTS3 | 0.5B | ❌ | 2.79 | 77.1 | 1.52 | 79.0 | - | - |
| DiTAR | 0.6B | ❌ | 1.69 | 73.5 | 1.02 | 75.3 | - | - |
| CosyVoice3 | 0.5B | ❌ | 2.02 | 71.8 | 1.16 | 78.0 | 6.08 | 75.8 |
| CosyVoice3 | 1.5B | ❌ | 2.22 | 72.0 | 1.12 | 78.1 | 5.83 | 75.8 |
| Seed-TTS | - | ❌ | 2.25 | 76.2 | 1.12 | 79.6 | 7.59 | 77.6 |
| MiniMax-Speech | - | ❌ | 1.65 | 69.2 | 0.83 | 78.3 | - | - |
| F5-TTS | 0.3B | ✅ | 2.00 | 67.0 | 1.53 | 76.0 | 8.67 | 71.3 |
| MaskGCT | 1B | ✅ | 2.62 | 71.7 | 2.27 | 77.4 | - | - |
| CosyVoice | 0.3B | ✅ | 4.29 | 60.9 | 3.63 | 72.3 | 11.75 | 70.9 |
| CosyVoice2 | 0.5B | ✅ | 3.09 | 65.9 | 1.38 | 75.7 | 6.83 | 72.4 |
| SparkTTS | 0.5B | ✅ | 3.14 | 57.3 | 1.54 | 66.0 | - | - |
| FireRedTTS | 0.5B | ✅ | 3.82 | 46.0 | 1.51 | 63.5 | 17.45 | 62.1 |
| FireRedTTS-2 | 1.5B | ✅ | 1.95 | 66.5 | 1.14 | 73.6 | - | - |
| Qwen2.5-Omni | 7B | ✅ | 2.72 | 63.2 | 1.70 | 75.2 | 7.97 | 74.7 |
| Qwen3-Omni | 30B-A3B | ✅ | 1.39 | - | 1.07 | - | - | - |
| OpenAudio-s1-mini | 0.5B | ✅ | 1.94 | 55.0 | 1.18 | 68.5 | 23.37 | 64.3 |
| IndexTTS2 | 1.5B | ✅ | 2.23 | 70.6 | 1.03 | 76.5 | 7.12 | 75.5 |
| VibeVoice | 1.5B | ✅ | 3.04 | 68.9 | 1.16 | 74.4 | - | - |
| HiggsAudio-v2 | 3B | ✅ | 2.44 | 67.7 | 1.50 | 74.0 | 55.07 | 65.6 |
| VoxCPM-0.5B | 0.6B | ✅ | 1.85 | 72.9 | 0.93 | 77.2 | 8.87 | 73.0 |
| VoxCPM1.5 | 0.8B | ✅ | 2.12 | 71.4 | 1.18 | 77.0 | 7.74 | 73.1 |
| MOSS-TTS | ✅ | 1.85 | 73.4 | 1.20 | 78.8 | - | - | |
| Qwen3-TTS | 1.7B | ✅ | 1.23 | 71.7 | 1.22 | 77.0 | 6.76 | 74.8 |
| FishAudio S2 | 4B | ✅ | 0.99 | - | 0.54 | - | 5.99 | - |
| LongCat-Audio-DiT | 3.5B | ✅ | 1.50 | 78.6 | 1.09 | 81.8 | 6.04 | 79.7 |
| VoxCPM2 | 2B | ✅ | 1.84 | 75.3 | 0.97 | 79.5 | 8.13 | 75.3 |
CV3-eval
CV3-eval 多语言 WER/CER(⬇) 结果(点击展开)
| 模型 | zh | en | hard-zh | hard-en | ja | ko | de | es | fr | it | ru |
|---|---|---|---|---|---|---|---|---|---|---|---|
| CosyVoice2 | 4.08 | 6.32 | 12.58 | 11.96 | 9.13 | 19.7 | - | - | - | - | - |
| CosyVoice3-1.5B | 3.91 | 4.99 | 9.77 | 10.55 | 7.57 | 5.69 | 6.43 | 4.47 | 11.8 | 10.5 | 6.64 |
| Fish Audio S2 | 2.65 | 2.43 | 9.10 | 4.40 | 3.96 | 2.76 | 2.22 | 2.00 | 6.26 | 2.04 | 2.78 |
| VoxCPM2 | 3.65 | 5.00 | 8.55 | 8.48 | 5.96 | 5.69 | 4.77 | 3.80 | 9.85 | 4.25 | 5.21 |
MiniMax-Multilingual-Test
Minimax-MLS-test 的 WER(⬇) 结果(点击展开)
| 语言 | Minimax | ElevenLabs | Qwen3-TTS | FishAudio S2 | VoxCPM2 |
|---|---|---|---|---|---|
| 阿拉伯语 | 1.665 | 1.666 | – | 3.500 | 13.046 |
| 粤语 | 34.111 | 51.513 | – | 30.670 | 38.584 |
| 中文 | 2.252 | 16.026 | 0.928 | 0.730 | 1.136 |
| 捷克语 | 3.875 | 2.108 | – | 2.840 | 24.132 |
| 荷兰语 | 1.143 | 0.803 | – | 0.990 | 0.913 |
| 英语 | 2.164 | 2.339 | 0.934 | 1.620 | 2.289 |
| 芬兰语 | 4.666 | 2.964 | – | 3.330 | 2.632 |
| 法语 | 4.099 | 5.216 | 2.858 | 3.050 | 4.534 |
| 德语 | 1.906 | 0.572 | 1.235 | 0.550 | 0.679 |
| 希腊语 | 2.016 | 0.991 | – | 5.740 | 2.844 |
| 印地语 | 6.962 | 5.827 | – | 14.640 | 19.699 |
| 印度尼西亚语 | 1.237 | 1.059 | – | 1.460 | 1.084 |
| 意大利语 | 1.543 | 1.743 | 0.948 | 1.270 | 1.563 |
| 日语 | 3.519 | 10.646 | 3.823 | 2.760 | 4.628 |
| 韩语 | 1.747 | 1.865 | 1.755 | 1.180 | 1.962 |
| 波兰语 | 1.415 | 0.766 | – | 1.260 | 1.141 |
| 葡萄牙语 | 1.877 | 1.331 | 1.526 | 1.140 | 1.938 |
| 罗马尼亚语 | 2.878 | 1.347 | – | 10.740 | 21.577 |
| 俄语 | 4.281 | 3.878 | 3.212 | 2.400 | 3.634 |
| 西班牙语 | 1.029 | 1.084 | 1.126 | 0.910 | 1.438 |
| 泰语 | 2.701 | 73.936 | – | 4.230 | 2.961 |
| 土耳其语 | 1.52 | 0.699 | – | 0.870 | 0.817 |
| 乌克兰语 | 1.082 | 0.997 | – | 2.300 | 6.316 |
| 越南语 | 0.88 | 73.415 | – | 7.410 | 3.307 |
Minimax-MLS-test 的 SIM(⬆) 结果(点击展开)
| 语言 | Minimax | ElevenLabs | Qwen3-TTS | FishAudio S2 | VoxCPM2 |
|---|---|---|---|---|---|
| 阿拉伯语 | 73.6 | 70.6 | – | 75.0 | 79.1 |
| 粤语 | 77.8 | 67.0 | – | 80.5 | 83.5 |
| 中文 | 78.0 | 67.7 | 79.9 | 81.6 | 82.5 |
| 捷克语 | 79.6 | 68.5 | – | 79.8 | 78.3 |
| 荷兰语 | 73.8 | 68.0 | – | 73.0 | 80.8 |
| 英语 | 75.6 | 61.3 | 77.5 | 79.7 | 85.4 |
| 芬兰语 | 83.5 | 75.9 | – | 81.9 | 89.0 |
| 法语 | 62.8 | 53.5 | 62.8 | 69.8 | 73.5 |
| 德语 | 73.3 | 61.4 | 77.5 | 76.7 | 80.3 |
| 希腊语 | 82.6 | 73.3 | – | 79.5 | 86.0 |
| 印地语 | 81.8 | 73.0 | – | 82.1 | 85.6 |
| 印度尼西亚语 | 72.9 | 66.0 | – | 76.3 | 80.0 |
| 意大利语 | 69.9 | 57.9 | 81.7 | 74.7 | 78.0 |
| 日语 | 77.6 | 73.8 | 78.8 | 79.6 | 82.8 |
| 韩语 | 77.6 | 70.0 | 79.9 | 81.7 | 83.3 |
| 波兰语 | 80.2 | 72.9 | – | 81.9 | 88.4 |
| 葡萄牙语 | 80.5 | 71.1 | 81.7 | 78.1 | 83.7 |
| 罗马尼亚语 | 80.9 | 69.9 | – | 73.3 | 79.7 |
| 俄语 | 76.1 | 67.6 | 79.2 | 79.0 | 81.1 |
| 西班牙语 | 76.2 | 61.5 | 81.4 | 77.6 | 83.1 |
| 泰语 | 80.0 | 58.8 | – | 78.6 | 84.0 |
| 土耳其语 | 77.9 | 59.6 | – | 83.5 | 87.1 |
| 乌克兰语 | 73.0 | 64.7 | – | 74.7 | 79.8 |
| 越南语 | 74.3 | 36.9 | – | 74.0 | 80.6 |
内部 30 语言 ASR 基准测试
我们还额外运行了一个内部多语言可懂度基准测试,包含 30 种语言 × 500 个样本。ASR 转录通过 Gemini 3.1 Flash Lite API 进行评估。
内部 30 语言 ASR 基准测试(点击展开)
| 语言 | 指标 | VoxCPM2 | Fish S2-Pro |
|---|---|---|---|
| ar (阿拉伯语) | CER | 1.23% | 0.30% |
| da (丹麦语) | WER | 2.70% | 3.52% |
| de (德语) | WER | 0.96% | 0.64% |
| el (希腊语) | WER | 3.17% | 4.61% |
| en (英语) | WER | 0.42% | 1.03% |
| es (西班牙语) | WER | 1.33% | 0.64% |
| fi (芬兰语) | WER | 2.24% | 2.80% |
| fr (法语) | WER | 2.16% | 2.34% |
| he (希伯来语) | CER | 2.98% | 15.27% |
| hi (印地语) | CER | 0.79% | 0.91% |
| id (印尼语) | WER | 1.36% | 1.68% |
| it (意大利语) | WER | 1.65% | 1.08% |
| ja (日语) | CER | 2.40% | 1.82% |
| km (高棉语) | CER | 2.05% | 75.15% |
| ko (韩语) | CER | 0.95% | 0.29% |
| lo (老挝语) | CER | 1.90% | 87.40% |
| ms (马来语) | WER | 1.75% | 1.41% |
| my (缅甸语) | CER | 1.42% | 85.27% |
| nl (荷兰语) | WER | 1.25% | 1.68% |
| no (挪威语) | WER | 2.49% | 3.76% |
| pl (波兰语) | WER | 1.90% | 1.65% |
| pt (葡萄牙语) | WER | 1.48% | 1.49% |
| ru (俄语) | WER | 0.90% | 0.86% |
| sv (瑞典语) | WER | 2.22% | 2.63% |
| sw (斯瓦希里语) | CER | 1.07% | 2.02% |
| th (泰语) | CER | 0.94% | 1.92% |
| tl (他加禄语) | WER | 2.63% | 4.00% |
| tr (土耳其语) | WER | 1.65% | 1.65% |
| vi (越南语) | WER | 1.56% | 5.56% |
| zh (中文) | CER | 0.92% | 1.02% |
| 平均值(30种语言) | 1.68% | - |
InstructTTSEval
指令引导的声音设计结果(点击展开)
| 模型 | InstructTTSEval-ZH | InstructTTSEval-EN | ||||
|---|---|---|---|---|---|---|
| APS⬆ | DSD⬆ | RP⬆ | APS⬆ | DSD⬆ | RP⬆ | |
| Hume | – | – | – | 83.0 | 75.3 | 54.3 |
| VoxInstruct | 47.5 | 52.3 | 42.6 | 54.9 | 57.0 | 39.3 |
| Parler-tts-mini | – | – | – | 63.4 | 48.7 | 28.6 |
| Parler-tts-large | – | – | – | 60.0 | 45.9 | 31.2 |
| PromptTTS | – | – | – | 64.3 | 47.2 | 31.4 |
| PromptStyle | – | – | – | 57.4 | 46.4 | 30.9 |
| VoiceSculptor | 75.7 | 64.7 | 61.5 | – | – | – |
| Mimo-Audio-7B-Instruct | 75.7 | 74.3 | 61.5 | 80.6 | 77.6 | 59.5 |
| Qwen3TTS-12Hz-1.7B-VD | 85.2 | 81.1 | 65.1 | 82.9 | 82.4 | 68.4 |
| VoxCPM2 | 85.2 | 71.5 | 60.8 | 84.2 | 83.2 | 71.4 |
⚙️ 微调
VoxCPM 支持 全量微调(SFT) 和 LoRA 微调。只需 5–10 分钟 的音频,即可适配特定的说话人、语言或领域。
# LoRA 微调(参数高效,推荐)
python scripts/train_voxcpm_finetune.py \
--config_path conf/voxcpm_v2/voxcpm_finetune_lora.yaml
# 全量微调
python scripts/train_voxcpm_finetune.py \
--config_path conf/voxcpm_v2/voxcpm_finetune_all.yaml
# WebUI 训练与推理
python lora_ft_webui.py # 然后打开 http://localhost:7860完整指南 → 微调指南(数据准备、配置、训练、LoRA 热切换、FAQ)
📚 文档
| 主题 | 链接 |
|---|---|
| 快速入门与安装 | 快速入门 |
| 使用指南与示例 | 用户指南 |
| VoxCPM 系列 | 模型 |
| 微调(SFT 与 LoRA) | 微调指南 |
| FAQ 与故障排除 | FAQ |
🌟 生态系统与社区
| 项目 | 描述 |
|---|---|
| Nano-vLLM | 高吞吐、快速 GPU 推理服务 |
| vLLM-Omni | 官方 vLLM 全模态推理服务 for VoxCPM2 — PagedAttention、OpenAI 兼容 API |
| VoxCPM.cpp | GGML/GGUF:CPU、CUDA、Vulkan 推理 |
| VoxCPM-ONNX | ONNX 导出,支持 CPU 推理 |
| VoxCPMANE | Apple Neural Engine 后端 |
| voxcpm_rs | Rust 重实现版 |
| ComfyUI-VoxCPM | ComfyUI 节点工作流 |
| ComfyUI_RH_VoxCPM | 功能完备的 ComfyUI VoxCPM 2 工作流,支持多说话人生成、LoRA 和自动 ASR |
| ComfyUI-VoxCPMTTS | ComfyUI TTS 扩展 |
| TTS WebUI | 基于浏览器的 TTS 扩展 |
请参阅文档中的完整生态系统。社区项目不由 OpenBMB 官方维护。做出了很酷的东西?请提交 Issue 或 PR 来添加!
⚠️ 风险与限制
- 潜在滥用风险: VoxCPM 的语音克隆能生成高度逼真的合成语音。严禁将 VoxCPM 用于冒充、欺诈或虚假信息传播。我们强烈建议明确标注所有 AI 生成的内容。
- 可控生成稳定性: 语音设计和可控语音克隆的结果可能因运行次数而异——您可以尝试生成 1~3 次以获得期望的语音或风格。我们正在积极提高可控性的一致性。
- 语言覆盖范围: VoxCPM2 官方支持 30 种语言。对于未列入列表的语言,欢迎直接测试或基于自有数据进行微调。我们计划在后续版本中扩大语言覆盖范围。
- 使用: 本模型以 Apache-2.0 许可证发布。对于生产部署,建议根据您的使用场景进行充分的测试和安全评估。
📖 引用
如果您觉得 VoxCPM 有用,请考虑引用我们的工作并点亮 ⭐ 仓库!
@article{zhou2026voxcpm2,
title = {VoxCPM2 Technical Report},
author = {Zhou, Yixuan and Zeng, Guoyang and Liu, Xin and Li, Xiang and Yu, Renjie and Gui, Jiancheng and Wu, Jiaheng and Wang, Ziyang and Shen, Xudong and Ye, Runchuan and Zhang, Zhisheng and Zhou, Jiuyang and Bai, Bingsong and Sun, Weiyue and Deng, Mengyuan and Shi, Qundong and Wu, Zhiyong and Liu, Zhiyuan},
journal = {arXiv preprint arXiv:2606.06928},
year = {2026},
}
@article{zhou2025voxcpm,
title = {Voxcpm: Tokenizer-free TTS for context-aware speech generation and true-to-life voice cloning},
author = {Zhou, Yixuan and Zeng, Guoyang and Liu, Xin and Li, Xiang and Yu, Renjie and Wang, Ziyang and Ye, Runchuan and Sun, Weiyue and Gui, Jiancheng and Li, Kehan and Wu, Zhiyong and Liu, Zhiyuan},
journal = {arXiv preprint arXiv:2509.24650},
year = {2025}
}📄 许可证
VoxCPM 模型权重和代码在 Apache-2.0 许可证下开源。
🙏 致谢
- DiTAR —— 扩散自回归骨干网络
- MiniCPM-4 —— 语言模型基座
- CosyVoice —— 基于 Flow Matching 的 LocDiT 实现
- DAC —— 音频 VAE 骨干网络
- 我们的社区用户——感谢你们试用 VoxCPM、报告问题、分享想法和贡献代码,你们的支持让项目变得更好