视频转写
粘贴 YouTube/TikTok/B站等链接,用 AI 转写并总结视频与播客内容
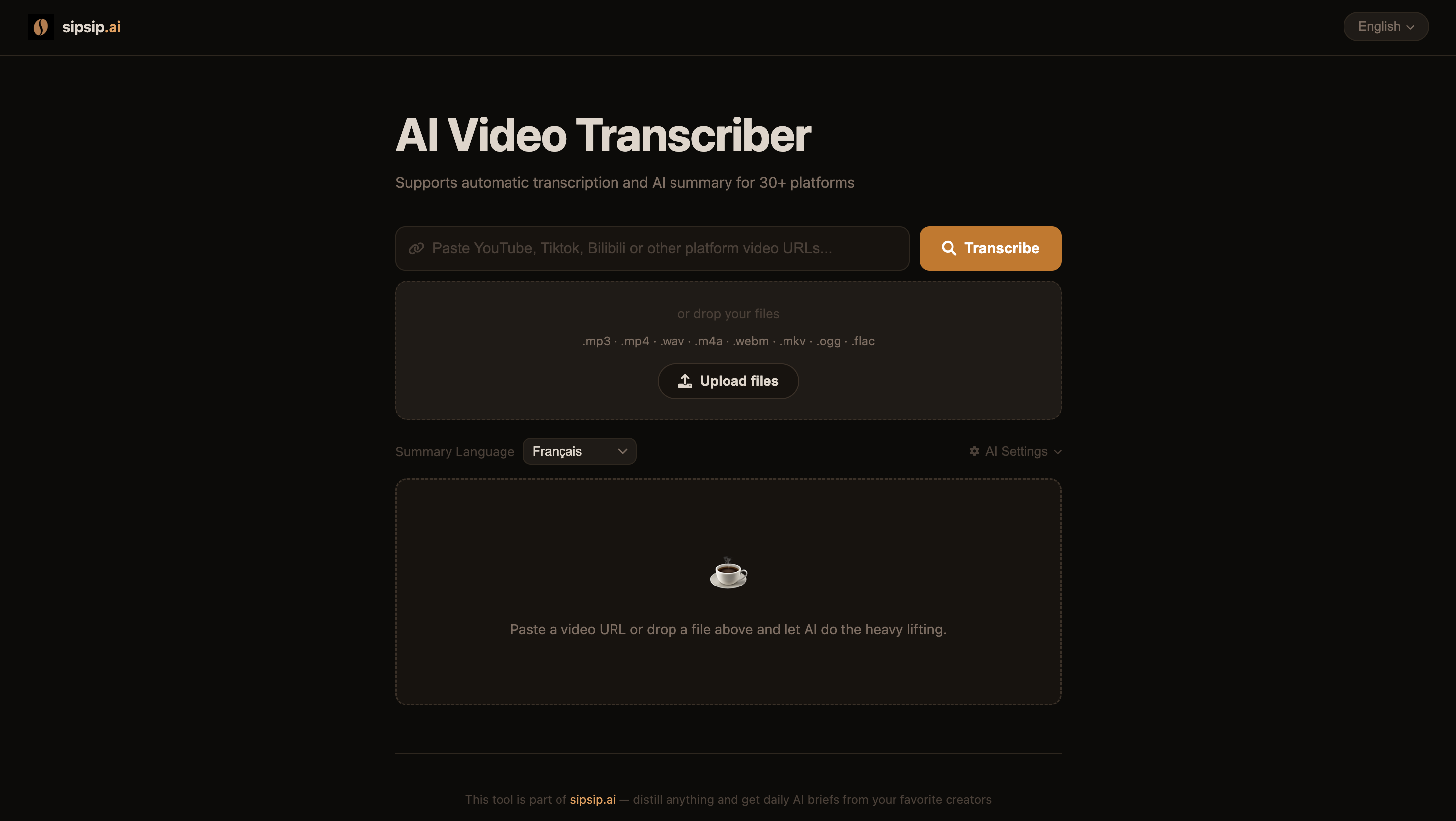
AI Video Transcriber
English | 中文
一款基于AI的视频和播客转录与摘要工具——粘贴来自 YouTube、TikTok、Bilibili、Apple Podcasts、SoundCloud等30多个平台的链接,或上传本地文件本地文件(音频、视频或纯文本)。
✨ 功能特性
- 🎥 多平台支持:支持YouTube、TikTok、Bilibili、Apple Podcasts、SoundCloud等30多个平台
- 📁 本地文件上传:支持拖拽或点击选择文件——支持的格式包括
.txt(视为转录文本)、.mp3、.mp4、.m4a、.wav、.webm、.mkv、.mkv、.ogg、.flac。媒体文件会通过FFmpeg标准化后交由Whisper处理;与URL处理流程相同的优化→翻译→摘要管线 - ⚡ 字幕优先架构:对于自带字幕的平台(如YouTube),可直接提取转录文本,无需下载音频。Whisper仅作为备用方案,大幅提升整体处理速度
- 🗣️ 智能转录:当无字幕可用时,使用Faster-Whisper实现高精度语音转文字
- 🤖 AI文本优化:自动修正拼写错误、补全句子、智能分段
- 🌍 多语言摘要:支持生成多种语言的智能摘要
- 🔧 自带模型:在UI中直接配置任意兼容OpenAI的API端点(OpenAI、OpenRouter、本地LLM等)——输入API Base URL和API Key,点击获取即可自动发现所有可用模型并选择
- ⚙️ 条件翻译:当摘要语言与源语言不同时,自动翻译转录文本
- 📱 移动端友好:完美支持移动设备
🚀 快速开始
前提条件
- Python 3.8+
- FFmpeg(yt-dlp音频提取和上传媒体标准化必需)
- 任意兼容OpenAI的提供商(OpenAI、OpenRouter等)的API密钥——直接在UI中配置,无需服务器端环境变量
安装
方法一:自动安装
# 克隆仓库
git clone https://github.com/wendy7756/AI-Video-Transcriber.git
cd AI-Video-Transcriber
# 运行安装脚本
chmod +x install.sh
./install.sh方法二:Docker
# 克隆仓库
git clone https://github.com/wendy7756/AI-Video-Transcriber.git
cd AI-Video-Transcriber
# 使用Docker Compose(最简单)
cp .env.example .env
# 如需服务器端默认配置,编辑.env文件(可选)
docker-compose up -d
# 或直接使用Docker
docker build -t ai-video-transcriber .
docker run -p 8000:8000 --env-file .env ai-video-transcriber该镜像使用Python 3.12(Debian Bookworm),升级pip/setuptools/wheel,然后从requirements.txt安装依赖——与当前Python版本下全新本地虚拟环境相同的版本约束。
方法三:手动安装
- 安装Python依赖
# macOS(PEP 668)强烈建议使用虚拟环境
python3 -m venv venv
source venv/bin/activate
python -m pip install --upgrade pip
pip install -r requirements.txt- 安装FFmpeg
# macOS
brew install ffmpeg
# Ubuntu/Debian
sudo apt update && sudo apt install ffmpeg
# CentOS/RHEL
sudo yum install ffmpeg- 配置环境变量 (可选)
# 如需服务器端默认配置,设置以下变量——否则通过UI配置
export OPENAI_API_KEY="your_api_key_here"
export OPENAI_BASE_URL="https://openrouter.ai/api/v1" # 任意兼容OpenAI的端点启动服务
python3 start.py服务启动后,打开浏览器访问http://localhost:8000
生产模式(推荐用于长视频)
为避免长时间处理过程中避免SSE断开连接,请使用生产模式启动(禁用热重载):
python3 start.py --prod这能确保长时间任务(30-60分钟以上)中SSE连接稳定。
使用显式环境变量运行(示例)
source venv/bin/activate
export OPENAI_API_KEY=your_api_key_here # 可选:服务器端默认值
# export OPENAI_BASE_URL=https://openrouter.ai/api/v1 # 可选:服务器端默认值
python3 start.py --prod📖 使用指南
- 选择输入方式——URL或文件
- 视频/播客URL:将YouTube、Bilibili或其他支持平台的链接粘贴到输入框
- 本地文件:将文件拖拽到虚线上传区域(或点击浏览)。点击转录按钮即可开始任务;上传文件与URL使用相同的API路由(
POST /api/process-video,multipartfile),便于反向代理仅允许该路径
- 选择摘要语言:从输入框旁边的下拉菜单中选择输出语言
- (可选)配置AI模型:点击AI设置展开面板
- 输入API Base URL(如
https://openrouter.ai/api/v1)和API Key - 点击获取自动加载该提供商的所有模型
- 选择所需模型——留空则使用服务器默认值
- 输入API Base URL(如
- 开始处理:点击转录按钮。对于URL任务,进度条会显示当前模式:
- ⚡ 字幕(绿色)——找到原生字幕,数秒内提取转录文本
- 🎙 Whisper(琥珀色)——无可用字幕,下载音频进行转录
对于本地上传,媒体文件会通过FFmpeg标准化后由Whisper转录;纯文本**
.txt**文件会跳过下载/Whisper,直接进入文本处理文本管线(优化→摘要,语言不同时进行翻译)。
- 查看结果:查看优化后的转录文本和AI摘要
- 如果转录文本语言≠所选摘要语言,翻译标签页签会自动出现
- 下载文件:保存Markdown格式的文件(转录文本/翻译/摘要)
🛠️ 技术架构
后端技术栈
- FastAPI:现代Python Web框架
- yt-dlp:视频下载与处理
- FFmpeg:音频提取与本地上传标准化(Whisper所需的单声道16kHz)
- Faster-Whisper:高效语音转录
- OpenAI API:智能文本摘要
前端技术栈
- HTML5 + CSS3:响应式界面设计
- JavaScript (ES6+):现代前端交互
- Marked.js:Markdown渲染
- Font Awesome:图标库
项目结构
AI-Video-Transcriber/
├── backend/ # 后端代码
│ ├── main.py # FastAPI主应用
│ ├── video_processor.py # 视频处理模块
│ ├── transcriber.py # 转录模块
│ ├── summarizer.py # 摘要模块
│ ├── translator.py # 翻译模块
│ └── llm_sanitize.py # 后处理LLM输出后处理(去除模板化内容)
├── static/ # 前端文件
│ ├── index.html # 主页面
│ └── app.js # 前端逻辑
├── temp/ # 临时文件目录
├── Dockerfile # Docker镜像配置
├── docker-compose.yml # Docker Compose配置
├── .dockerignore # Docker忽略规则
├── .env.example # 环境变量模板
├── requirements.txt # Python依赖
├── start.py # 启动脚本
└── README.md # 项目文档⚙️ 配置选项
环境变量
| 变量 | 描述 | 默认值 | 必需 |
|---|---|---|---|
OPENAI_API_KEY | API 密钥(服务端默认值) | - | 否——也可在 UI 中设置 |
HOST | 服务器地址 | 0.0.0.0 | 否 |
PORT | 服务器端口 | 8000 | 否 |
WHISPER_MODEL_SIZE | Whisper 模型尺寸 | base | 否 |
UPLOAD_MAX_MB | 本地文件最大上传大小(MB) | 200 | 否 |
可选专用端点 POST /api/process-upload 存在,其行为与向 /api/process-video 发送 file 相同。
Whisper 模型尺寸选项
| 模型 | 参数 | 仅英文 | 多语言 | 速度 | 内存占用 |
|---|---|---|---|---|---|
| tiny | 39 M | ✓ | ✓ | 快 | 低 |
| base | 74 M | ✓ | ✓ | 中等 | 低 |
| small | 244 M | ✓ | ✓ | 中等 | 中等 |
| medium | 769 M | ✓ | ✓ | 慢 | 中等 |
| large | 1550 M | ✗ | ✓ | 非常慢 | 高 |
🔧 常见问题
问:为什么转录速度慢?
答:转录速度取决于视频长度、Whisper 模型大小和硬件性能。尝试使用更小的模型(如 tiny 或 base)来提高速度。
问:支持哪些视频平台?
答:yt-dlp 支持的所有平台,包括但不限于:YouTube、TikTok、Facebook、Instagram、Twitter、Bilibili、优酷、爱奇艺、腾讯视频等。
问:本地文件类型和大小限制是什么?
答:允许的扩展名包括 .txt、.mp3、.mp4、.m4a、.wav、.webm、.mkv、.ogg、.flac。默认每个文件最大 200 MB;可通过服务器上的 UPLOAD_MAX_MB 环境变量覆盖。
问:如果 AI 优化功能不可用怎么办?
答:AI 功能需要来自任何兼容 OpenAI 的提供商(OpenAI、OpenRouter 等)的 API 密钥。您可以直接在 UI 中的 AI 设置 面板中输入——无需重启服务器。或者,将 OPENAI_API_KEY 设置为环境变量作为服务端默认值。
问:启动/使用服务时遇到 HTTP 500 错误,为什么?
答:大多数情况下是环境配置问题,而非代码错误。请检查:
- 确保已激活虚拟环境:
source venv/bin/activate - 在虚拟环境中安装依赖:
pip install -r requirements.txt - 在 AI 设置 面板中配置您的 API 密钥,或将
OPENAI_API_KEY设置为环境变量 - 安装 FFmpeg:
brew install ffmpeg(macOS)/sudo apt install ffmpeg(Debian/Ubuntu) - 如果端口 8000 被占用,停止旧进程或更改
PORT
问:如何处理长视频?
答:系统可以处理任意长度的视频,但处理时间会相应增加。对于非常长的视频,考虑使用更小的 Whisper 模型。
问:如何使用 Docker 部署?
答:Docker 提供了最简单的部署方法:
前提条件:
- 从 https://www.docker.com/products/docker-desktop/ 安装 Docker Desktop
- 确保 Docker 服务正在运行
快速启动:
# 克隆并设置
git clone https://github.com/wendy7756/AI-Video-Transcriber.git
cd AI-Video-Transcriber
cp .env.example .env
# 编辑 .env 文件设置服务端默认值(可选)
# 使用 Docker Compose 启动(推荐)
docker-compose up -d
# 或手动构建并运行
docker build -t ai-video-transcriber .
docker run -p 8000:8000 --env-file .env ai-video-transcriber常见 Docker 问题:
- 端口冲突:如果 8000 被占用,更改端口映射
-p 8001:8000 - 权限不足:确保 Docker Desktop 正在运行且您有适当权限
- 构建失败:检查磁盘空间(需要约 2GB 可用空间)和网络连接
- 容器无法启动:使用
docker logs <container_id>查看 Docker 日志
Docker 命令:
# 查看运行中的容器
docker ps
# 查看容器日志
docker logs ai-video-transcriber-ai-video-transcriber-1
# 停止服务
docker-compose down
# 更改后重新构建
docker-compose build --no-cache问:内存要求是什么?
答:内存使用量取决于部署方式和工作负载:
Docker 部署:
- 基础内存:空闲容器约 128MB
- 处理期间:500MB – 2GB,取决于视频长度和 Whisper 模型
- Docker 镜像大小:需要约 1.6GB 磁盘空间
- 推荐:4GB+ RAM 以实现流畅运行
传统部署:
- 基础内存:FastAPI 服务器约 50–100MB
- Whisper 模型内存使用:
tiny:约 150MBbase:约 250MBsmall:约 750MBmedium:约 1.5GBlarge:约 3GB
- 峰值使用:基础 + 模型 + 视频处理(额外约 500MB)
内存优化技巧:
# 使用更小的 Whisper 模型以减少内存使用
WHISPER_MODEL_SIZE=tiny # 或 base
# 对于 Docker,可根据需要限制容器内存
docker run -m 1g -p 8000:8000 --env-file .env ai-video-transcriber
# 监控内存使用
docker stats ai-video-transcriber-ai-video-transcriber-1问:网络连接错误或超时?
答:如果在视频下载或 API 调用过程中遇到网络相关错误,请尝试以下解决方案:
常见网络问题:
- 视频下载失败,出现“无法提取”或超时错误
- OpenAI API 调用返回连接超时或 DNS 解析失败
- Docker 镜像拉取失败或速度极慢
解决方案:
- 切换 VPN/代理:尝试连接到不同的 VPN 服务器或更改代理设置
- 检查网络稳定性:确保您的互联网连接稳定
- 网络更改后重试:更改网络设置后等待 30–60 秒再重试
- 使用替代端点:如果使用自定义 OpenAI 端点,请验证它们可从您的网络访问
- Docker 网络问题:如果容器网络失败,重启 Docker Desktop
快速网络测试:
# 测试视频平台访问
curl -I https://www.youtube.com/
# 测试您的 AI 提供商端点
curl -I https://openrouter.ai
# 测试 Docker Hub 访问
docker pull hello-world🎯 支持的语言
转录
- 通过 Whisper 支持 100+ 种语言
- 自动语言检测
- 对主要语言具有高准确度
摘要生成
- 英语
- 中文(简体)
- 日语
- 韩语
- 西班牙语
- 法语
- 德语
- 葡萄牙语
- 俄语
- 阿拉伯语
- 以及更多……
📈 性能提示
-
硬件要求:
- 最低:4GB RAM,双核 CPU
- 推荐:8GB RAM,四核 CPU
- 理想:16GB RAM,多核 CPU,SSD 存储
-
处理时间估算:
视频长度 字幕模式 Whisper 模式 备注 1 分钟 ~5 秒 30 秒–1 分钟 字幕模式无需下载音频 5 分钟 ~10 秒 2–5 分钟 YouTube 自动字幕触发字幕模式 15 分钟 ~15 秒 5–15 分钟 大多数 YouTube 视频支持字幕模式 30 分钟以上 ~20 秒 15–60 分钟 播客/纯音频始终使用 Whisper
🤝 贡献
我们欢迎 Issue 和 Pull Request!
- Fork 本仓库
- 创建功能分支(
git checkout -b feature/AmazingFeature) - 提交您的更改(
git commit -m '添加了一些 AmazingFeature') - 推送到分支(
git push origin feature/AmazingFeature) - 打开 Pull Request
致谢
- yt-dlp - 强大的视频下载工具
- Faster-Whisper - 高效的 Whisper 实现
- FastAPI - 现代 Python Web 框架
- OpenAI - 智能文本处理 API
📞 联系
如有问题或建议,请提交 Issue 或联系 Wendy。
🚀 体验完整产品 — sipsip.ai
此工具是 sipsip.ai 的开源部分。
完整产品更进一步:
- 📧 每日邮件简报 — 关注你喜欢的创作者,每天早上在收件箱中获取 AI 精选摘要
- ⚡ 按需转录和总结任何视频或播客
- 🌐 所有功能均支持多语言
免费开始 — 无需信用卡。
➡️ sipsip.ai
⭐ 星标历史
如果你觉得这个项目有帮助,请考虑给它一个星标!