学术科研
面向学术研究全流程的技能套件,覆盖检索、写作、引用核查、同行评审到定稿
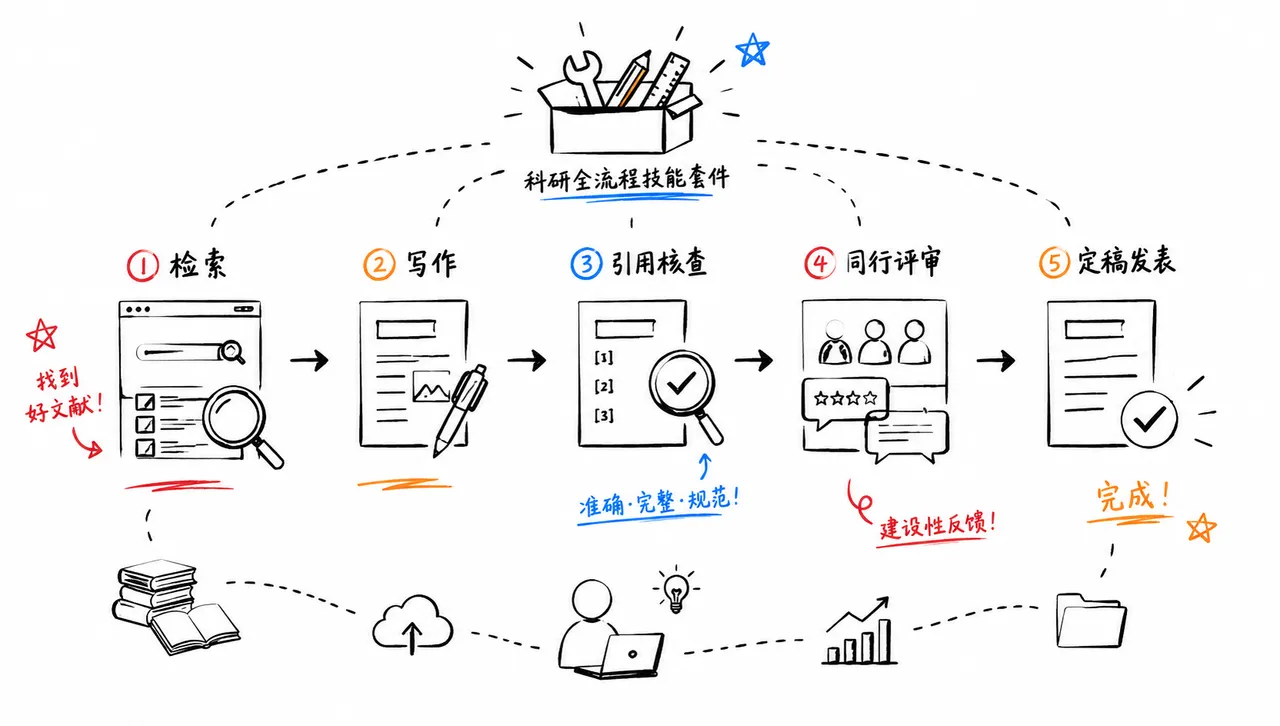
![]()
一套为学术研究打造的全面 Claude Code 技能集,覆盖从研究到发表的完整流程。
30秒快速安装(Claude Code CLI / VS Code / JetBrains,v3.7.0+):
/plugin marketplace add Imbad0202/academic-research-skills
/plugin install academic-research-skills然后运行 /ars-plan 通过苏格拉底式对话梳理你的论文结构,或者跳转到快速安装查看前置条件和传统的符号链接流程。
AI是你的副驾驶,不是主驾驶。 这个工具不会替你把论文写完。它处理的是琐碎工作——查找参考文献、格式化引用、验证数据、检查逻辑一致性——这样你就可以专注于真正需要你大脑的部分:定义问题、选择方法、解释数据意味着什么,以及写出“我认为……”之后的句子。
与“人类化”工具不同,这个工具不会帮你掩盖使用AI的事实。它帮助你写得更出色。Style Calibration 从你过往的作品中学习你的文风。Writing Quality Check 捕捉那些让行文感觉像机器生成的模式。目标是质量,而非欺骗。
为什么是人在回路中,而非完全自动化?
Lu 等 (2026,Nature 651:914-919) 构建了The AI Scientist——第一个完全自主的AI研究系统,通过盲审顶会ML领域(ICLR 2025 研讨会,评分6.33/10,研讨会平均4.87)发表了论文。其局限性部分列举了任何完全自主AI研究管线都会继承的失败模式:实现错误、结果幻觉、依赖捷径、将错误视为洞见、方法论捏造、思维框架锁定、引用幻觉。
ARS 建立在这样的前提上:人类研究者借助AI增强,能够比单独任何一方更好地避免这些失败模式。Stage 2.5 和 Stage 4.5 的完整性检查点运行一个7模式拦截检查清单(见 academic-pipeline/references/ai_research_failure_modes.md);审阅者提供一个可选的校准模式,针对用户提供的黄金标准集测量自身的假阴性率/假阳性率。
Zhao 等(2026-05)审计了 arXiv、bioRxiv、SSRN 和 PMC 上 250 万篇论文中的 1.11 亿条参考文献。他们的保守估计是,仅 2025 年就有 146,932 条幻觉引用,并在 2024 年中期观察到一个拐点;对于 bioRxiv 到 PMC 的配对,他们报告了 85.3% 的预印本到发表版本的持续率。该论文将“用于支持引用文献实际并未做出的主张的真实引用”描述为一个开放性挑战。ARS v3.7.1 为来源出处添加了信任链前置信息;v3.7.3 添加了定位符基础设施(三层引用锚点),用于未来的声明级审计,并在引用时显示预警风险信号(ARS 内部将声明可信度差距标记为“L3”,这是 ARS 术语,非论文术语)。v3.7.x 的改进动机来自 Zhao 等人在语料库规模上的发现;ARS 本身的语料库规模评估仍是未来工作。
v3.8 弥补了 L3 差距的后半部分。v3.7.3 使每条引用都携带了一个定位锚点;v3.8 添加了一个可选的审计通道(ARS_CLAIM_AUDIT=1),该通道根据每个定位锚点获取被引来源,并判断声明是否得到实际支持。五个新的 HIGH-WARN 分类(声明不支持、否定约束违反、虚构引用、无定位锚点、未引用约束违反)通过格式化终端硬门控拒绝输出。校准作为一个 20 元黄金标准集提供,接受阈值 FNR<0.15 + FPR<0.10;启用计划推迟到根据 v3.8 规范第5节完成校准证据之后。
v3.3 的灵感来自PaperOrchestra(Song, Song, Pfister & Yoon, 2026,Google):Semantic Scholar API 验证、防泄漏协议、VLM 图表验证和评分轨迹追踪。
架构与管线
👉 docs/ARCHITECTURE.md — 完整的管线视图:流程图、逐阶段矩阵、数据访问流程、技能依赖图、质量门控和模式列表。
架构文档取代了原来写在这里的长篇管线描述。关于哪个阶段运行什么的所有内容现在都在同一个地方。
快速安装
前置条件
- Claude Code(最新版;插件打包需要较新的版本)
- 导出
ANTHROPIC_API_KEY,或在首次运行claude时设置 - 可选: Pandoc 用于生成 DOCX,tectonic + Source Han Serif TC 用于生成 APA 7.0 PDF(Markdown 输出不需要这些)
插件安装(v3.7.0+,推荐):
/plugin marketplace add Imbad0202/academic-research-skills
/plugin install academic-research-skills验证是否可用: 运行 /ars-plan 并描述你正在撰写的论文——ARS 将启动一段苏格拉底式对话,梳理章节结构。如果想一次性测试,可以尝试 /ars-lit-review "your topic"。
👉 docs/SETUP.md — 完整指南:安装 Claude Code、设置 API 密钥、可选 Pandoc/tectonic 用于 DOCX/PDF、跨模型验证(ARS_CROSS_MODEL),以及五种安装方法(插件、项目技能、全局技能、claude.ai 项目、仓库克隆)。
使用 Codex CLI? 请改为安装兄弟分发版:Imbad0202/academic-research-skills-codex — 相同的工作流内容,Codex 原生打包为单个 $academic-research-suite 技能,并带有 ars-* 别名。
性能与成本
👉 docs/PERFORMANCE.md — 每种模式的 token 预算、全管线估算(一篇 15k 单词的论文约 $4–6),以及推荐的 Claude Code 设置(跳过权限;可选 Agent 团队)。
指南与文章
- 学术写作不应该是独角戏 — 全管线演练(英文)
- 學術寫作不該是一個人的事:一套開源 AI 協作工具如何改變研究者的工作流 — 完整使用指南(繁體中文)
功能概览
- 深度研究(Deep Research) — 13 个 agent 组成的研究团队,带有苏格拉底引导模式、PRISMA 系统综述、意图检测、对话健康监控、可选跨模型 DA,以及 Semantic Scholar API 验证。
- 学术论文(Academic Paper) — 12 个 agent 的论文写作,包含 Style Calibration、Writing Quality Check、LaTeX 加固、可视化、修订辅导、引用转换、防泄漏协议和 VLM 图表验证。
- 学术论文审稿(Academic Paper Reviewer) — 7 个 agent 的多视角同行评审,带有 0–100 质量评分标准(主编 + 3 个动态审稿人 + 魔鬼代言人)、让步阈值协议、攻击强度保持、可选跨模型 DA 批评/校准、修改与重新提交可追溯矩阵,以及只读约束。
- 学术管线(Academic Pipeline) — 10 阶段管线编排器,带有自适应检查点、声明验证、材料护照、可选
repro_lock、可选跨模型完整性验证、对话中途强化,以及评分轨迹追踪。 - 数据访问级别元数据(v3.3.2+) — 每个技能声明
data_access_level(raw/redacted/verified_only);由scripts/check_data_access_level.py强制执行。模式改编自 Anthropic 的 automated-w2s-researcher(2026)。见shared/ground_truth_isolation_pattern.md。 - 任务类型标注(v3.3.2+) — 每个技能声明
task_type(open-ended或outcome-gradable)。所有当前 ARS 技能均为open-ended。 - 基准报告模式(v3.3.5+) — JSON Schema + lint,用于诚实的基准比较。见
shared/benchmark_report_pattern.md。 - 成果可复现锁定文件(v3.3.5+) — 材料护照上的可选
repro_lock子块。配置文档,非重放保证——LLM 输出不可字节级复现。见shared/artifact_reproducibility_pattern.md。 - 实验来源信息录入(#260) — 材料护照上的可选
experiment_provenance[],记录学者外部运行的实验(ARS 从不运行实验),手稿声明通过claim_intent_manifest.planned_experiment_ids[]与之关联。完整性检查点(Stage 2.5/4.5)审计每个有实验支持的声明与已声明来源的一致性——ALIGNED/OVERSTATED/NOT_SUPPORTED_BY_PROVENANCE/PROVENANCE_INSUFFICIENT——但不判断实验本身是否正确。一个失败关闭的experiment_intake_declaration使“你是否运行了实验?”成为 Stage 1 的显式决策(即使是仅文献的研究也声明no_experiments_declared)。见shared/handoff_schemas.md的“实验来源信息录入 (#260)”部分。
示例:真实流水线输出
查看来自一个真实 10 阶段流水线运行的完整产物——包括同行评审报告、完整性验证报告以及最终论文:
| 产物 | 描述 |
|---|---|
| 最终论文(英文版) | APA 7.0 格式,LaTeX 编译 |
| 最终论文(中文版) | 中文版本,APA 7.0 |
| 完整性报告——预审 | 阶段 2.5:发现 15 条虚构参考文献 + 3 处统计错误 |
| 完整性报告——最终版 | 阶段 4.5:确认零回归 |
| 同行评审第一轮 | EIC + 3 位审稿人 + 魔鬼代言人 |
| 复审 | 修订后的验证 |
| 同行评审第二轮 | 后续评审 |
| 给审稿人的回复 | 作者逐条回复 |
| 发表后审计报告 | 独立的完整参考文献审计:发现 3 轮完整性检查共遗漏 21/68 个问题 |
配套工具:实验代理
如果你的研究在写作前涉及运行实验(代码或人类研究),实验代理技能填补了 ARS 阶段 1(研究)和阶段 2(写作)之间的空白。
ARS 阶段 1 研究 → 研究问题简报 + 方法论蓝图
↓
实验代理 → 运行/管理实验 → 验证结果
↓
ARS 阶段 2 写作 → 使用经过验证的实验结果撰写论文功能:执行代码实验(Python、R 等)并实时监控,管理带有 IRB 伦理检查清单的人类研究方案,通过 11 种谬误检测进行统计解读,并验证可重复性。
如何配合使用:在阶段 1 之后暂停 ARS 流水线,在单独的实验代理会话中运行实验,然后将结果(连同材料护照)带回到 ARS 阶段 2。ARS 无需任何修改。设置说明请参见实验代理 README。
阶段 1 摄入声明 (#260):在阶段 1,ARS 会检测本次运行是否会包含基于实验的声明,并在材料护照上设置一个故障闭合的 experiment_intake_declaration。如果你在外部运行了实验,研究者需为每个实验输入一条 experiment_provenance[] 记录(包含 experiment_id、嵌套的 repro_lock、planned_vs_executed[]、negative_results[]、known_limitations[]),此时声明被设置为 experiments_declared;如果没有,则设置为 no_experiments_declared。该声明是每份 #260 之后的护照所必需的——即使运行未涉及任何实验,也必须声明 no_experiments_declared,从而防止因遗忘 provenance 区块而悄然绕过完整性检查。experiment_id 在此摄入点被冻结;后续写作者通过 planned_experiment_ids[] 引用它们。
教学端配套工具:教学技能将 ARS 架构(技能组合、共享契约、阶段化关卡、课程护照)应用于学术生活的教学端——课程设计 → 授课 → 评估 → 交付 → 反思;其 sotl 模式将课堂探究项目交给 ARS 的深度研究 / 学术论文功能以完成发表阶段。
使用方法
快速开始
# 启动完整的研究流水线
你:"我想写一篇关于 AI 对高等教育质量保障影响的研究论文"
# 使用苏格拉底式引导开始
你:"引导我研究 AI 在教育评估中的应用"
# 通过引导规划撰写论文
你:"引导我撰写一篇关于人口下降的论文"
# 评审现有论文
你:"评审这篇论文"(然后提供论文)
# 检查流水线状态
你:"状态"单项技能
深度研究(8 种模式)
"研究 AI 对高等教育的影响" → 完整模式
"给我一份关于 X 的简要简报" → 快速模式
"使用 PRISMA 对 X 进行系统综述" → 系统综述模式
"引导我研究 X" → 苏格拉底模式(引导式)
"核查这些主张的事实" → 事实核查模式
"对 X 进行文献综述" → 文献综述模式
"以 WHY/HOW/WHAT 格式比较这些论文" → 三维扫描模式
"评审这篇论文的研究质量" → 评审模式学术论文(11 种模式)
"撰写一篇关于 X 的论文" → 完整模式
"引导我撰写一篇论文" → 规划模式(引导式)
"构建论文大纲" → 仅大纲模式
"我有一篇草稿,这里是审稿人意见" → 修订模式
"将这些审稿人意见解析为路线图" → 修订指导模式
"为这篇论文撰写摘要" → 仅摘要模式
"将其转变为文献综述论文" → 文献综述模式
"转换为 LaTeX" / "将引用转换为 IEEE 格式" → 格式转换模式
"检查引用" → 引用检查模式
"为 NeurIPS 生成 AI 披露声明" → 披露模式
"根据审稿意见审计我的 rebuttal 草稿" → rebuttal 审计模式学术论文审稿人(6 种模式)
"评审这篇论文" → 完整模式(EIC + R1/R2/R3 + 魔鬼代言人)
"快速评估这篇论文" → 快速模式
"引导我改进这篇论文" → 引导模式
"检查方法论" → 方法论聚焦模式
"验证修订" → 复审模式
"根据我的黄金标准校准这位审稿人" → 校准模式学术流水线(编排器)
"我想写一篇完整的研究论文" → 从阶段 1 开始的完整流水线
"我已经有一篇论文,请评审它" → 在阶段 2.5 中途进入(先做完整性检查)
"我收到了审稿人意见" → 在阶段 4 中途进入流水线以阶段 6:流程总结结束——自动生成论文创作过程记录,包含 6 个维度的协作质量评估(1–100 分制)。
支持的语言
- 繁体中文(繁體中文)——当用户使用中文书写时默认
- 英语——当用户使用英语书写时默认
- 学术论文的双语摘要(中文 + 英文)
使用其他语言? 苏格拉底模式(深度研究)和规划模式(学术论文)使用基于意图的激活——它们检测请求的含义,而非特定关键词。这意味着它们无需修改即可在任何语言下工作。
然而,通用的“触发关键词”部分(决定技能是否被激活)仍然列出了英文和繁体中文关键词。如果你发现技能在你的语言中无法可靠激活,你可以将你的语言关键词添加到每个
SKILL.md文件的### 触发关键词部分,以提高匹配的准确性。
支持的引用格式
- APA 7.0(默认,包含中文引用规则)
- Chicago(注释与作者-日期)
- MLA
- IEEE
- Vancouver
支持的论文结构
- IMRaD(实证研究)
- 主题式文献综述
- 理论分析
- 案例研究
- 政策简报
- 会议论文
技能详情
每个智能体的职责和每个阶段的产物现在位于 docs/ARCHITECTURE.md 中。版本号在此固定,因此发布元数据保留在一个位置。
深度研究(v2.10.0)
13 智能体研究团队。模式:完整、快速、审阅、文献综述、三方扫描、事实核查、苏格拉底式、系统综述。完整智能体列表和产物:参见 ARCHITECTURE.md §3。
学术论文(v3.2.0)
12 智能体论文写作流程。模式:完整、计划、仅大纲、修订、修订教练、仅摘要、文献综述、格式转换、引用检查、披露、反驳审计。输出:MD + DOCX(通过 Pandoc(可用时))+ LaTeX(APA 7.0 apa7 类 / IEEE / Chicago)→ 通过 tectonic 生成 PDF。完整智能体列表和每阶段职责:参见 ARCHITECTURE.md §3。
学术论文审稿人(v1.10.0)
7 智能体多视角审阅,配有 0-100 质量评分标准。模式:完整、重新审阅、快速、方法聚焦、引导、校准。决策映射: ≥80 接受,65-79 小幅修改,50-64 大幅修改,<50 拒绝。首轮审阅团队与窄域重新审阅团队的边界:参见 ARCHITECTURE.md §3 阶段 3 / 阶段 3’。
学术工作流(v3.12.1)
10 阶段编排器,包含完整性验证、两阶段审阅、苏格拉底式辅导和协作评估。工作流保证:每个阶段需要用户确认检查点;完整性验证(阶段 2.5 + 4.5)不可跳过;R&R 可追溯性矩阵(模式 11)独立验证作者的修订声明。v3.4 在阶段 2.5 / 4.5 加入了合规智能体(PRISMA-trAIce + RAISE)。v3.5 在每个 FULL/SLIM 检查点以及工作流完成时加入了协作深度观察者(collaboration_depth_agent,仅建议性质——从不阻塞)。强制性完整性门控(2.5 / 4.5)显式跳过观察者,以免稀释合规检查。基于 Wang & Zhang(2026),IJETHE 23:11。每个阶段的矩阵(含智能体、产物和门控):参见 ARCHITECTURE.md §3。
v3.0 优化:关于 AI 结构限制的发现
发生了什么
在使用 ARS 撰写关于高等教育中 AI 的反思文章时,我遇到了三个无论提示工程如何都无法解决的结构性问题:
-
框架锁定:我要求 AI 对自己的论点进行魔鬼代言人辩论。它确实做了——四轮,每一轮都比前一更精细。但每一轮都停留在我设定的框架内。魔鬼代言人攻击论点,却从未攻击前提。它从未问过“我们是否在讨论正确的问题?”这正是导致 v2.7 压力测试中 31% 引用错误率的相同模式:验证 AI 和生成 AI 共享相同的认知框架。
-
压力之下的谄媚:每次我挑战魔鬼代言人的攻击时,它都过快地让步。它撤回发现的速度比提出发现的速度更快。模型的训练奖励对话和谐——因此“用户反驳了”被视为攻击错误的证据,而实际上往往只是用户坚持己见。
-
意图误判:苏格拉底导师不断地试图收敛并产生交付物(“要我把这个写下来吗?”),而我仍在探索阶段。它无法区分“用户想要深入的哲学讨论”与“用户想要一个研究问题摘要”。两者看起来都是参与,但需要相反的 AI 行为。
我们改变了什么(v3.0)
魔鬼代言人——让步阈值协议(deep-research + academic-paper-reviewer)
- 魔鬼代言人现在必须在回应前对每个反驳进行 1-5 级评分
- 仅在评分 ≥4(反驳直接以证据回应核心攻击)时才允许让步
- 评分 ≤3:坚持立场并重新陈述原始攻击
- 反谄媚规则:不允许连续让步,跟踪让步率,每个检查点后检测框架锁定
苏格拉底导师——意图检测层(deep-research)
- 在对话开始时和每 3 轮次将用户意图分类为探索型 vs 目标导向型
- 探索模式:禁用自动收敛,将最大轮次提升至 60,禁止“要我总结吗?”等提示
- 目标导向模式:标准收敛行为
- 反过早结束规则:在探索模式下,由用户决定何时停止
苏格拉底导师——对话健康指标(deep-research)
- 每 5 轮次进行静默自我评估,评估三个维度:持续同意、冲突回避、过早收敛
- 当检测到同意模式时自动注入挑战性问题
- 对用户不可见(防止操纵),但日志可在会后审查中查看
为什么这很重要
这些优化并没有解决 AI 的结构限制——它们使限制变得可见和可控。魔鬼代言人最终如果被足够用力推动仍会让步。苏格拉底导师仍然会有一定的收敛偏差。但现在有了明确的检查点来减缓谄媚,迫使魔鬼代言人证明让步的合理性,并防止导师在用户准备好之前结束。
更深层的教训:AI 素养不在于学习将 AI 作为工具使用、遵循伦理规则或害怕 AI 风险。而在于深入接触 AI 以发现其自身的结构限制——以及在此过程中发现自己思维的局限。
许可协议
本作品采用 CC-BY-NC 4.0 许可。
您可以自由地:
- 分享——复制并重新分发本材料
- 改编——基于本材料进行重混、转换和创作
在以下条款下:
- 署名——您必须提供适当的署名
- 非商业性使用——您不得将本材料用于商业目的
署名格式:
基于 吴政宜(Cheng-I Wu)的 Academic Research Skills
https://github.com/Imbad0202/academic-research-skills贡献者
吴政宜(Cheng-I Wu)——作者和维护者
aspi6246——贡献者。v3.1 优化灵感来自 Claude-Code-Skills-for-Academics 中的模式:只读约束模式、反模式编码作为一等设计、认知框架方法(教授“如何思考”而非仅步骤)以及精益技能规模哲学。
mchesbro1——贡献者。最初提议并为 academic-paper-reviewer/references/top_journals_by_field.md 草拟了 IS 八大期刊篮子(Issue #5)。
cloudenochcsis——贡献者。将 IS 部分从 八大期刊篮子 扩展为完整的 资深学者十一大期刊篮子——增加了 Decision Support Systems、Information & Management 和 Information and Organization(Issue #7、PR #8)。来源:AIS 资深学者顶级期刊列表。
eltociear (Ikko Eltociear Ashimine) — 贡献者。翻译了日文 README(README.ja-JP.md)(PR #161)。
xpfo-go (xpfo) — 贡献者。翻译了简体中文 README(README.zh-CN.md)(PR #181)。
Yaobin29 — 贡献者。在 PR #433 中提出了审稿人回复工具;其中的 deep-research three-way-scan 模式和 academic-paper rebuttal-audit 模式(源自该 PR 的 audit 概念)已在 v3.12.1 中集成。
更新日志
v3.12.1 (2026-06-15) — 审稿人回复分类模式(PR #433 集成)
此补丁版本将外部贡献中真正新颖的部分作为模式集成到现有技能中,遵循 ARS 基于模式的架构。新模式:
deep-researchthree-way-scan—— 一种轻量级的 WHY/HOW/WHAT 论文比较分类方法,介于quick和lit-review之间,包含每篇论文的短列表和跨论文综合(deep-research2.9.4 → 2.10.0);academic-paperrebuttal-audit—— 对作者现有的反驳/回复草稿,对照审稿意见进行独立的咨询性质问(每条意见的覆盖表 + 差距列表 + 语气/证据/误读风险标记),独立运行时不会生成任何内容,并明确抑制 Schema 11 / Material Passport 写入 /ready_to_submit(由带有变异覆盖的check_rebuttal_audit_guard()lint 强制执行);此外,revision-coach的范围扩展至反驳/异议姿态及非期刊场景,并新增/ars-3w+/ars-rebuttal-audit斜杠命令。根据输入形状路由:审稿意见 AND 草稿 →rebuttal-audit;仅有意见 →revision-coach。集成自 @Yaobin29 的 PR #433。套件模式数量从 25 增至 27(技能数量仍为 4)。请参阅CHANGELOG.md了解每个问题的详细信息。
v3.12.0 (2026-06-08) — Kong 自动研究特性线:实验溯源、图表保真度、跨论文矛盾、部分证据分解
此小版本发布了 Kong et al. (2026, arXiv:2605.18661) 的自动研究特性线以及部分证据陷阱分解工作,每项均经过独立审阅和合并。新特性: 实验溯源输入 + 声明→实验对齐 —— 一种基于模式、以证据分类账为中心的实验支持声明层,仅包含输入和对齐(学者在外部进行实验;ARS 从不执行实验)(#260);图表/表格保真度门控,检查图例解释是否源自数据,以及稿件是否引用了其支持的声明所对应的物证(#261);结构化的跨论文矛盾清单,使评估的论文对可枚举以供学者确认(#262);在引用判断器(#213)和编辑综合器(#214)两层中进行声明后子声明分解,填补了第 F.3.2 节中两层的部分证据陷阱。指导 + 解释层: 跨生成报告的审阅者的简洁输出 + 压力稳定边界强化(#274);同族 / 规则意识校准认识论注释(#273);将检索内容指令/数据边界作为常设原则(#367)。负面范围: Kong META(#255)在
POSITIONING.md中新增“被拒绝的机制”部分,列举了 ARS 不做的五种自主机制,以及两个 Tier D 设计经验文档。发布纪律 lint: 版本一致性不变量 5–7(#357)和 ARCHITECTURE 组件版本监控(#345)。此外,跨模型接地防护(#346 / #349 / #351)、引用门控缓存键和边界约束(#359 / #360 / #361)、评估黄金集(#250)以及 ACL/EMNLP 披露重新接地(#242)方面的正确性修复。新的模式、清单字段和所有不变量都是增量的且向后兼容。academic-pipeline跟踪套件版本 v3.12.0;其他三个技能版本不变。请参阅CHANGELOG.md了解每个问题的详细信息。
v3.11.1 (2026-06-06) — 发布后正确性、强化及溯源汇总
此补丁版本汇总了 v3.11.0 发布后发现的修复,每项均经独立审阅和合并:跨模型同意门控扩展至完整性验证 + 协作深度路径(#322)、每条目 OpenAlex + Crossref 回填并行化(#138),以及跨引用存在门控、v3.10 策略层、评估框架、领域证据概况和 #310 安全边界边缘情况(#323 / #327 / #328 / #329 / #331 / #332 / #333)的七个正确性/强化修复——包括两个 P1 修复(#327 领域概况激活在无交接路径上,#328 评估框架每个类别阈值门控)。无新功能,无破坏性模式变更。请参阅
CHANGELOG.md了解每个问题的详细信息。
v3.11.0 (2026-06-04) — 确定性引用验证门控(#182)
新增一个确定性引用存在验证门控,独立于 LLM 同行评审运行。每条引用的参考文献均与最多四个书目索引进行交叉检查——Semantic Scholar + OpenAlex + Crossref + 新的 arXiv 解析器(
scripts/arxiv_client.py,无需 API 密钥)——并将每条引用的lookup_verified状态({true, false, unresolvable})写入统一摘要,从而通过查找而不是依赖审稿人智能体来捕获具有可证明虚假 DOI/arXiv ID 的捏造引用。该门控继承 v3.10terminal_policies选择加入模式:检测始终运行,但lookup_verified == false行仅当用户选择加入terminal_policies.citation_existence == strict时才成为终止条件——默认行为是建议性的,可通过/ars-mark-read确认。false范围缩小为ID 键控不匹配(精确的 DOI/arXiv 查找可证明失败),因此合法但未被索引的人文/非英语/地区级引用保持unresolvable状态,永远不会阻塞(这是文档中记录的精度优先于召回率权衡)。附带持久的 SQLite 验证缓存(~/.cache/ars/verification.db,90 天 TTL)及/ars-cache-invalidate命令,独立verification_gateAPI 和verify_passport.pyCLI,以及 v3.9.0 污染三角测量矩阵的四索引扩展(k=0..4)(均为建议性)。academic-pipeline跟踪套件版本 v3.11.0;其他三个技能版本不变。规范:docs/design/2026-05-21-v3.10-182-promote-citation-gate-spec.md(§0 修订 + C-V6)。
v3.10.0 (2026-06-01) — 三角测量策略层、Kong 调查采纳、评估框架、限定写入防护
小版本捆绑发布:选择加入的污染三角测量终端策略层(#127——默认引用行为字节等价于 v3.9.0);Kong et al. 2026 调查采纳——反驳承诺分类账(#256/#266/#268/#269)和学科相对领域证据概况(#259);v3.10 测量基础设施——通用评估黄金集 + 排名提升 CI 门控(#184);限定写入防护 MVP(#134)——一个确定性的
PreToolUse钩子,将 23 个单阶段智能体限制在其自己的阶段目录中,并禁止其使用 Bash(它们改用 Grep/Glob 和结构化编辑工具);/ars-mark-read插件命令(#190)及其到达即损坏的修复(#195);简体中文 README(#185);以及 CI 强化(#156/#155)。academic-paper→ v3.2.0,academic-paper-reviewer→ v1.10.0(针对承诺分类账和领域概况新增);academic-pipeline跟踪套件版本 v3.10.0。默认技能行为不变,除非选择加入严格的策略模式;唯一默认开启的变更就是 #134 防护,它约束了受限的子智能体,而非面向用户的输出。
v3.9.4.2 (2026-05-19) — PR #149 CI discipline gates 的发布后热修复(codex 发布后审查)
对 PR #149(7 个 CI discipline gates)的 codex 发布后审查发现了 4 个 P2 级别的发现;v3.9.4.2 修复了其中 3 个。F1:
harness-retirement-monthly.yml添加了GH_REPO,使定时运行拥有仓库上下文以用于gh issue create。F2:release-cooldown.yml将PREV_TAG查找限制为v*标签,从而非发布标签无法绕过冷却期。F3:release-cooldown.yml还读取注解标签的 subject 并接受hot-fix拼写(v3.9.2 之前是一个假阴性热修复)。PR #157 后续:[skip-cooldown]覆盖现在同时从提交信息和注解标签信息中读取(自举修复——此标签的冷却期绕过证明了 F2+F3 端到端工作)。F4(test-count-monotonic hardening)已回滚,因为它暴露了scripts/包中已有的问题,跟踪为 #154(已由 PR #158 修复)+ 重试 #155。关闭 #152。后续:#155, #156。
v3.9.4.1 (2026-05-19) — v3.9.4 时间验证的发布后热修复(#135 codex 发布后)
对 v3.9.4 的 codex 发布后审查捕获了 4 个真实 Bug,这些被每个任务的子代理审查者遗漏了。热修复修补了全部 4 个:(1)
audit()现在将citation_provenance通过线路传到 P2 和 P4——当引用 slug 的confidence: low或conflict时,验证器会发出TEMPORAL-METADATA-MISSING,而不是使用时间线日期作为基准(规范 §3.4 的第一方安全检查曾经被破坏)。(2)_date_to_interval解析所有符合模式的日期形状,包括YYYY-MM(Crossref 月份精度)和YYYY-MM-DD..YYYY-MM-DD(区间);v3.9.4 静默地在这些形状上ValueError并跳过了检查。(3) P4 现在在引用标记缺失时绑定直接日期捕获——像 “The 2026 policy enabled the 2020 rollout” 这样的句子现在实际触发了。(4)citation_provenance.schema.json的confidence:highallOf 现在除了非空之外还需要存在性(then.required),从而关闭了缺失属性的绕过。1561 通过(与 v3.9.4 基线相比新增 12 个测试,0 回归)。ARCHITECTURE.md 已与当前状态对齐(之前停留在 v3.8.0 版本过时)。
v3.9.4 (2026-05-18) — #135 时间验证层(咨询性)
在 Phase 4 → 5 边界处的确定性咨询验证器,涵盖 5 种时间故障模式(P1 回顾算术、P2 时间错位引用、P3 比较器未实例化、P4 因果倒置、P5 直示现在)。新的 Phase 2 同级
timeline_extraction_agent拥有phase2_investigation/timeline.yaml+phase2_investigation/citation_provenance.yaml。验证脚本scripts/temporal_integrity_audit.py以确定性方式运行 5 遍。M3 时间完整性铁律已添加到report_compiler_agent+draft_writer_agent。M6-最小化:Crossrefissued+ pdftotext 覆盖第一方验证。M7-最小化:日期来源 + 比较器实例化。M5-存根:仅用户声明的version_family_id。对literature_corpus_entry、claim_audit_result、claim_intent_manifest零修改。bibliography_agent未修改(F2 不变性)。3 个新的 sidecar 模式。覆盖率估计:基线 55-70% / 加上 M7 最小化 65-75%。1549 通过(新增 44 个,0 回归)。
v3.9.3 (2026-05-18) — #128 内务整理(共享客户端工具 + 去重解析器)
纯重构 + 来自 v3.9.0
/simplify积压的一个潜在 Bug 修复。提取了scripts/_text_similarity.py(3 路客户端去重:normalize / similarity / threshold / retry 常量)+scripts/_passport_yaml.py(2 路迁移工具去重:ruamel.yaml round-trip 配置)+ 私有_resolve_by_doi_then_title辅助函数(2 路解析器主体去重,保留 §3.4 / §3.5 API 表面)。将限流测量标准化为整个 OpenAlex + Crossref 使用time.monotonic(之前是time.time,对 NTP 不安全),与 Semantic Scholar 对齐。所有 5 个模块级交叉导入上的双路径导入基础架构(优先同级,命名空间包回退)保留了SemanticScholarUnavailable的类身份,并额外修复了 2 个潜在损坏的import scripts.X路径。1505 通过(新增 23 个,0 回归)。#128 §4(每条目并行化 OA + CR)转移到 #138。
v3.9.2 (2026-05-18) — #133 阶段边界热修复
#133 关闭(热修复层)。长期架构修复作为 v3.10 动态指挥器跟踪在 #134 中。新增:CLAUDE.md 中的路由澄清门(跨阶段材料 → 用 a-d 选项澄清,而非静默分派),22 个单阶段代理获得提示硬围栏(
## Phase Boundary (v3.9.2)),16 个多阶段 / 阶段正交 / 跨阶段元代理有意不围栏(诚实框架——纯文本安慰剂造成虚假强制执行的假象),咨询验证器scripts/check_pipeline_integrity.py事后检测 #133 模式。行为冒烟测试与跨模型抽查(100% Opus 4.7,≥75% Sonnet + GPT-5.5)。
v3.9.1 (2026-05-18) — #129 + #130 客户端加固
v3.9.0 热修复。将 OpenAlex / Crossref 响应读取失败包装为
*Unavailable(#129);保护check_claim_audit_consistency免受非字符串manifest_id影响(#130)。规范无变化。
v3.9.0 (2026-05-17) — #102 跨索引三角测量
#102 关闭。v3.7.3 交付了单索引(Semantic Scholar)污染检测;v3.9.0 扩展到三索引三角测量(S2 + OpenAlex + Crossref)作为仅咨询证据。在
contamination_signals上新增两个可选布尔字段(openalex_unmatched、crossref_unmatched);手动录入的非规则对称扩展。终结器增加了一个 4 层咨询矩阵(在存在的*_unmatched字段上 k=0/1/2/3),并为 k=1/k_max=1 的 S2-only 情况保留了 v3.7.3 遗留的CONTAMINATED-UNMATCHED。格式化器传递白名单从 3 个后缀扩展到 9 个;拒绝规则 1-10 根据 R-L3-2-E 不变。策略层(严格模式、硬阻塞层、venue_type/triangulation_policy)推迟到 v3.10 根据规范 §2.3。k=3 标记为CONTAMINATED-TRIANGULATION-UNMATCHED(描述可观测值,非推断原因)。3 条新的硬性规则:R-L3-2-C(k 在存在的字段上计算)、R-L3-2-D(无 API 推断分类)、R-L3-2-E(拒绝列表不变;传递白名单扩展)。
迁移: v3.7.3 语料库——运行 python scripts/migrate_literature_corpus_to_v3_9_0.py PATH 来回填两个新字段。v3.7.3 之前的语料库——先运行 migrate_literature_corpus_to_v3_7_3.py,然后运行 v3.9.0 迁移(根据规范 §3.7 菊花链连接;v3.9.0 工具仅作用于已经带有 contamination_signals.semantic_scholar_unmatched 的条目)。
v3.8.2 (2026-05-17) — #118 未引用 audit_tool_failure 表面化
#118 关闭。
ARS_CLAIM_AUDIT=1未引用约束判断路径之前静默地用{"judgment": "NOT_VIOLATED"}替换JudgeInvocationError,抑制了临时判断器故障时的 HIGH-WARN 约束检查。v3.8.2 将这些故障通过一个专用的uncited_audit_failures[]聚合路由到 MED-WARN 咨询层,镜像引用的路径 INV-14 行,但使用专用模式,因为claim_audit_result.ref_slug是必需的,而未引用路径没有可绑定的引用。来自 #118 问题主体中的四个选项 1..4 权衡落在了选项 2(新聚合)——选项 4(重新抛出并中止)因对不稳定判断器的审计覆盖损失而被拒绝。
- 新的
uncited_audit_failure.schema.json聚合(规范§3.6)。每条未引用句子×清单对一条记录,其中约束判断器抛出了JudgeInvocationError。与引用路径INV-14相同的故障类枚举(judge_timeout/judge_api_error/judge_parse_error/cache_corruption/retrieval_api_error/retrieval_timeout/retrieval_network_error)。rule_version: D4-c-v1-uaf-v1。 - UAF-INV-1..UAF-INV-6 检查(规范§6规则4d)。
finding_id唯一性,scoped_manifest_id交叉数组完整性,manifest_claim_id非空时(M, C)对完整性,每个(句子, 清单)去重,rationale的fault_class前缀,相对于constraint_violations[]的跨聚合互斥性。 - Finalizer §5 MED-WARN咨询行:注解
[CLAIM-AUDIT-TOOL-FAILURE-UNCITED — <fault-class>],门控通过(重试下一轮补救)。Formatter REFUSE列表不变——UAF是咨询性的。 - 流水线集成(
scripts/claim_audit_pipeline.py):第1211-1224行移除的吞没站点;JudgeInvocationError现在发射一行UAF +continue到下一个(句子, 清单)对。没有假的NOT_VIOLATED进入constraint_violations[]。 - 测试:新增18个(15个schema/lint测试TSUAFUncitedAuditFailureInvariants + 3个流水线集成测试TP23UncitedJudgeOutageEmitsUAF)。基线从694→712个测试,0回归。
- Agent文档(
academic-pipeline/agents/claim_ref_alignment_audit_agent.md):输出发射表增加第7行;错误处理表从3个面增加到4个面,包含未引用路径UAF行。
v3.8.0 (2026-05-16) — L3 声明忠实度定位器 + 审计(配对里程碑)
v3.7.3 + v3.8 端到端填补了L3(声明忠实度)差距。v3.7.3交付定位器基础设施——每条引用携带一个三层锚点,以便未来的审计能获取引用的段落。v3.8交付执行审计的审计通道,这些审计消费那些锚点,判断引用的源是否支持声明,并在格式化器硬门控处门控拒绝HIGH-WARN违规。此版本还捆绑了自v3.7.0以来累积的5个审计追踪随附特性PR(#104/#105/#108/#111/#115)。
- #103 —
claim_ref_alignment_audit_agent(v3.8 PR #121)。可选用(ARS_CLAIM_AUDIT=1,默认关闭)阶段4→5审计Agent。针对每个采样的引用与检索到的摘录进行判断;发射claim_audit_results[]+claim_intent_manifests[]+claim_drifts[]+uncited_assertions[]+constraint_violations[]聚合。8行Finalizer矩阵将HIGH-WARN类(CLAIM-NOT-SUPPORTED / NEGATIVE-CONSTRAINT-VIOLATION / FABRICATED-REFERENCE / ANCHORLESS / CONSTRAINT-VIOLATION-UNCITED)通过格式化器REFUSE规则6-10路由。校准运行器附带20元组黄金集(T-C1 FNR<0.15 + FPR<0.10, T-C2 每个类别, T-C3 形状完整性)。经过8轮双轨审查(R1 codex + Gemini-3.1-pro-preview, R2-R8 仅在Gemini配额用完后codex-only);轨迹R1 4P1+2P2 → R8 0P1+4P2 交付门控。 - v3.7.3 — 三层引用发射 + 污染信号(PR #98)。
synthesis_agent/draft_writer_agent/report_compiler_agent增加## Three-Layer Citation Emission (v3.7.3)H2。每个<!--ref:slug-->携带<!--anchor:<kind>:<value>-->,其中<kind> ∈ {quote, page, section, paragraph, none}(引用锚点最多25个词,URL编码)。pipeline_orchestrator_agentFinalizer变为5个单元格,带优先级零的NO-LOCATOR检查。formatter_agent增加对[UNVERIFIED CITATION — NO QUOTE OR PAGE LOCATOR]的显式硬门控拒绝。literature_corpus_entry.schema.json增加可选contamination_signals: { preprint_post_llm_inflection, semantic_scholar_unmatched }对象。bibliography_agent在摄取时计算两个信号。11轮审查轨迹(Codex×10 + Gemini跨模型×1)关闭了22个发现。规范:docs/design/2026-05-12-ars-v3.7.3-claim-faithfulness-and-contaminated-source-spec.md。外部动机:Zhao et al. arXiv:2605.07723 (2026-05)。 - #108 — AI披露政策锚点渲染器(审计追踪随附 2026-05-14)。在现有场地追踪渲染器之外,增加了PRISMA-trAIce / ICMJE / Nature / IEEE政策锚点披露路径。
- #111 —
slr_lineage在系统综述→学术论文交接时发射(2026-05-15)。Schema 9可选布尔字段slr_lineage;生产者pipeline_orchestrator_agent在每个交接转换时写入;消费者disclosure模式根据§4.3 G2不变式追踪门控调度--policy-anchor=prisma-trAIce。 - #104 — README动机:Zhao et al. 语料规模证据锚点(2026-05-15)。README +
README.zh-TW.md的动机部分将v3.7.x系列置于Zhao等人发现146,932个幻觉引用的背景下。 - #105 — v3.7.3污染信号回填迁移工具(2026-05-15)。
scripts/migrate_literature_corpus_to_v3_7_3.py在v3.7.3之前的护照上反向计算两个污染信号。 - #115 — Semantic Scholar客户端成熟度(2026-05-15)。
scripts/semantic_scholar_client.py增加1请求/秒限速(检测到S2_API_KEY时降至0.1秒),URLError时的故障锁存器,以及用于长时间运行的跨护照批处理的reset_outage_latch()。
v3.7.0 (2026-05-05) — Claude Code 插件打包
插件打包升级:ARS现在可以通过
/plugin marketplace add Imbad0202/academic-research-skills+/plugin install academic-research-skills在Claude Code CLI / VS Code / JetBrains上一行安装。传统的git clone + symlink to ~/.claude/skills/流程仍然有效——两条路径都是头等公民。
- 插件清单 + 市场元数据(阶段1,PR #68)。
.claude-plugin/plugin.json声明套件(4个技能通过相对符号链接从skills/目录自动发现)。.claude-plugin/marketplace.json注册插件,使得单个GitHub托管的端点同时提供市场列表和插件源码。README +README.zh-TW.md+docs/SETUP.md包含双轨安装说明。 - 10个斜杠命令位于
commands/ars-*.md(阶段2.1,PR #69),将MODE_REGISTRY.md条目映射到/ars-<mode>触发器。模型路由在每个命令的前置元数据中固定——opus用于full和revision-coach(架构/审查解读深度),sonnet用于其他8个。根据项目政策,无Haiku。 - 3个插件随附的Agent位于
agents/*_agent.md(阶段2.1,PR #69),作为到deep-research/agents/中v3.6.7强化下游Agent的相对符号链接:synthesis_agent、research_architect_agent、report_compiler_agent。保留下划线文件名以保持scripts/check_v3_6_7_pattern_protection.py的硬固定路径和INV-3清单约束子句1不变式完整。符号链接(而非副本)保留单一真相源,并防止v3.6.7 §6反转扫描+ INV-1/2/3检查所关闭的模式C3攻击面。(在#413中物化为字节相同的副本——相对符号链接在未设置core.symlinks和zip下载安装时会破坏Windows检出;单一源保证移至scripts/check_agents_mirror_sync.py字节相等CI检查。) - **
model: inherit**添加到那三个源Agent前置元数据中选择inherit而非固定sonnet,以便运行ARS完整流水线的opus会话保留opus Agent(而不是被封顶)。用户的~/.claude/hooks/warn-agent-no-model.shPreToolUse钩子在调度边界处门控Haiku,因此inherit通过已经无Haiku的模型解析。 - SessionStart通知钩子位于
hooks/hooks.json+scripts/announce-ars-loaded.sh(阶段2.2,PR #70)。当插件加载时,钩子向LLM的第一轮注入一个additionalContext,列出10个斜杠命令、3个插件Agent以及一个令牌预算指针。startup和clear源值获得完整通知;resume和compact获得一行确认以避免消耗上下文。兼容Bash 3.2——在macOS内置/bin/bash上运行,无需brew install bash。 - 阶段2.2范围缩减:由于合同差距(SubagentStop负载不携带阶段/交付物信息,因此包装器必须半推断所需参数)和调用者类的边界(
run_codex_audit.sh第4-7行禁止在同一会话的LLM内调用;PostToolUse在生产会话内触发),SubagentStop → run_codex_audit.sh的代码审计钩子从v3.7.0中剥离。真正的审计钩子集成推迟到未来版本,届时ARS将获得阶段/交付物传播合同。参见docs/design/2026-04-30-ars-v3.7.0-plugin-packaging-roadmap.md更新说明2026-05-05(阶段2.2范围缩减)。 - **
docs/PERFORMANCE.md+.zh-TW.md**增加了一个“v3.7.0 插件Agent和模型路由”小节,解释inherit语义和当前3个Agent的范围边界。 - 跨三个PR的Codex审查链:8轮内联迭代 + 3轮全新PR级别审查,全部在合并前收敛到0个P0/P1/P2发现。阶段2.2的全新PR审查捕获了一个P2(未加引号的
${CLAUDE_PLUGIN_ROOT}破坏了包含空格的安装路径),内联轮次未发现——确认了将实现审查(内联)与合同审查(全新)分开的价值。 - 什么没有改变:四个技能目录、所有25个模式、Agent提示、schema文件和检查合同。插件打包仅添加新的顶层表面(
commands/、agents/、hooks/、.claude-plugin/、skills/符号链接目录、三个插件Agent的model: inherit前置元数据添加)。现有的4.3k克隆安装用户看不到破坏性更改。
v3.6.8 (2026-05-03) — 生成器-评估器契约门 (v3.6.6 规范发布)
命名说明:本次发布的是 v3.6.6 生成器-评估器契约 规范及实现。由于项目排期原因,v3.6.6 的工作在 v3.6.7 之后才落地;设计文档中契约门版本仍保留内部命名 v3.6.6,而套件版本标记为 v3.6.8 以保持 CHANGELOG 的单调递增性。
- Schema 13.1 (
shared/sprint_contract.schema.json) 在 Schema 13 基础上扩展了两个新的mode枚举值(writer_full+evaluator_full)、两个新的可选顶级字段(仅 writer 使用的pre_commitment_artifacts、仅 evaluator 使用的disagreement_handling),以及 12 个allOf分支,用于强制实施 reviewer- / writer- / evaluator 条件门控。现有 reviewer 契约在 Schema 13.1 下按字节等效验证(§3.6 零接触承诺)。 - 两个新增的已发布契约模板,位于
shared/contracts/writer/full.json(D1–D7, F1/F4/F2/F3/F0)和shared/contracts/evaluator/full.json(D1–D5, F1/F2/F3/F6/F4/F5/F0)。这些模板从规范分支上的设计时构件原子性地提升为已发布状态,同时进行了 Schema 13.1 升级。 academic-paper full内部的两阶段编排:Phase 4 拆分为 Phase 4a(writer 论文盲态预承诺)+ Phase 4b(writer 论文可见起草 + 自评分);Phase 6 拆分为 Phase 6a(evaluator 论文盲态预承诺)+ Phase 6b(evaluator 论文可见评分 + 决策)。编号为<phase4a_output>/<phase6a_output>的数据定界符与 v3.6.2 reviewer 模式一致。Lint 计数摘要:writer 3+4 / evaluator 5+5 / reviewer 5+6(reviewer 保持零接触)。academic-paperSKILL + agent 文件 新增了逐字## v3.6.6 Generator-Evaluator Contract Protocol块(SKILL.md 中 101 行,draft_writer_agent.md中 47 行,peer_reviewer_agent.md中 57 行)。SKILL.md 还新增了一个## Known limitations部分,包含针对 v3.6.7+ 的优雅降级和跨会话恢复的前瞻说明。- 验证器扩展:
scripts/check_sprint_contract.py新增 SC-* 模式门控审计(SC-5 + SC-11 仅 reviewer;SC-9 扩展到所有三个模式族)。17 个新测试将验证器单元测试计数从 54 增加到 71(包括正向测试 + 5 个 schema 分支负向测试 + 2 个 §3.6 reviewer 回归测试 + 6 个模式门控测试)。 - 清单 CI lint:
scripts/check_v3_6_6_ab_manifest.py对tests/fixtures/v3.6.6-ab/manifest.yaml实施 §6.2 清单 schema 和 §6.5 git 跟踪不变量检查。.github/workflows/spec-consistency.yml将 sprint 契约验证循环扩展为在现有 reviewer 循环之外同时遍历 writer 和 evaluator 模板目录,并运行新的清单 CI lint。 - A/B 证据夹具存根 位于
tests/fixtures/v3.6.6-ab/(30 个文件):manifest + README + 6 个 paper-A 输入/基线 + 1 个 paper-C 输入/基线 + Stage 3 reviewer 摘录 + 6 个 codex-judge 基线占位符。真实的夹具数据将在后续提交中填充,直到实现工作完全完成。
v3.6.7 (2026-04-30) — 下游代理模式保护(步骤 1+2)
- 针对 17 个已记录的幻觉/漂移模式中的 13 个,对三个下游代理进行了加固:
synthesis_agent(A1–A5 叙述侧)、research_architect_agent的调研设计模式(B1–B5 工具侧),以及report_compiler_agent的仅摘要模式(C1–C3 发布侧)。每个代理 prompt 现在都带有一个PATTERN PROTECTION (v3.6.7)块。 shared/references/下的四个参考文件:irb_terminology_glossary.md、psychometric_terminology_glossary.md、protected_hedging_phrases.md、word_count_conventions.md。这些参考文件带有操作契约,代理 prompts 通过路径引用这些契约。- 跨模型审计 prompt 模板 位于
shared/templates/codex_audit_multifile_template.md,包含七个审计维度和一个强制性的三部分 Section 4(f) 检查(针对report_compiler_agent包)。任何子检查失败都将被视为 P1 发现。 - 静态 lint + 29 项测试变异套件:
scripts/check_v3_6_7_pattern_protection.py强制检查保护子句的存在性和义务短语的格式;scripts/test_check_v3_6_7_pattern_protection.py保存 codex 审查证据,以便未来的检查器回归在 CI 中暴露。两者都已接入.github/workflows/spec-consistency.yml。 - Codex 审查历史:经过七轮
gpt-5.5+xhigh跨模型审查,达到 SHIP-OK 状态,零 P1+P2 发现。步骤 6(编排器运行时钩子)和步骤 8(合成评估用例)将在后续 PR 中发布。
v3.6.5 (2026-04-27) — 材料护照 literature_corpus[] 消费者集成
- 两个 Phase 1 文献消费者已接入:
deep-research/agents/bibliography_agent.md和academic-paper/agents/literature_strategist_agent.md。两者都遵循相同的五步语料库优先、搜索补充缺口流程(当护照包含非空literature_corpus[]时适用),并遵循相同的四条铁则(相同标准 / 禁止静默跳过 / 禁止语料库变异 / 解析失败时优雅回退)。 - 搜索策略报告中的 PRE-SCREENED 可重现性块:列举了 included / excluded / skipped 语料库条目,包含 F3 零命中注释以及 F4a–F4f 来源报告,这些报告围绕
obtained_via/obtained_at的部分声明进行组合。final_included = pre_screened_included[] ∪ external_included[]保持中立——书目条目或文献矩阵行上没有来源标签。 - 消费者协议参考 位于
academic-pipeline/references/literature_corpus_consumers.md,包含标准的 PRE-SCREENED 模板、BAD/GOOD 示例、四条铁则以及每个消费者的阅读说明。 - CI lint
scripts/check_corpus_consumer_protocol.py强制检查九条协议不变量,使用清单驱动的消费者列表(scripts/corpus_consumer_manifest.json)。 - Schema 9 注意事项已退役:
shared/handoff_schemas.md移除了 v3.6.4 中的“消费者侧集成推迟到 v3.6.5+”注意事项;替换为指向消费者协议的反向指针。 - 基于存在性检查,无 schema 变更,无新环境标志。解析失败将回退到仅外部数据库流程,并显示
[CORPUS PARSE FAILURE]的表面信息。citation_compliance_agent的语料库集成已推迟(目标版本待 v3.8 后确定)。 - 无重大变更。现有用户适配器无需修改即可正常工作。
v3.6.4 (2026-04-25) — 材料护照 literature_corpus[] 输入端口
literature_corpus[]字段 被添加到 Schema 9,作为用户自有文献的可选输入端口。每个条目符合shared/contracts/passport/literature_corpus_entry.schema.json(CSL-JSON 作者、年份、标题、source_pointer + 可选的abstract/user_notes私有字段)。- 语言无关的适配器契约 位于
academic-pipeline/references/adapters/overview.md:任何程序(任何语言)读取用户语料库来源都可以生成符合规范的passport.yaml+rejection_log.yaml。条目级错误软失败,适配器级错误硬失败,确定性排序。 - 三个参考 Python 适配器 位于
scripts/adapters/:folder_scan.py(PDF 文件系统)、zotero.py(Better BibTeX JSON 导出)、obsidian.py(库 frontmatter)。仅作为起点;用户需要为其他来源编写自己的适配器。 - 拒绝日志契约 位于
shared/contracts/passport/rejection_log.schema.json,包含封闭的分类原因值枚举;始终生成(无拒绝时为空)。 - CI 门控:
scripts/check_literature_corpus_schema.py验证 schema + 适配器示例;scripts/sync_adapter_docs.py --check防止 schema→文档漂移;新的pytest.yml工作流在路径过滤触发时运行scripts/adapters/tests/。 - v3.6.4 仅为输入端口:v3.6.4 发布了 schema 和适配器契约,未包含消费者集成。
bibliography_agent和literature_strategist_agent在 v3.6.5 中接入。
v3.6.3 (2026-04-23) — 可选 Passport 重置边界
- 可选 Passport 重置边界 (
ARS_PASSPORT_RESET=1)。将每个 FULL checkpoint 提升为上下文重置边界。新增resume_from_passport=<hash>模式,使用户能够仅通过 Material Passport 账本在全新的 Claude Code 会话中恢复。启用该标志后,systematic-review模式强制在每个 FULL checkpoint 进行重置;其他模式将重置视为由标志控制的默认行为。关闭标志则逐字节保留 v3.6.3 之前的行为。 - Schema 9 增加了仅追加的
reset_boundary[]账本,包含两种条目类型(kind: boundary+kind: resume)。哈希使用 JSON 规范格式 + SHA-256,并带有自引用安全性的规范占位符。可选的pending_decision处理 MANDATORY 分支选择。 - 新增 CI lint 脚本
scripts/check_passport_reset_contract.py:每次提及该标志时,必须附带指向权威协议文档的指针。 - 协议文档:
academic-pipeline/references/passport_as_reset_boundary.md。 - 更新了
docs/PERFORMANCE.md,增加了长时间运行会话的指导说明。 - 无破坏性变更。标志默认关闭。
v3.6.2 (2026-04-23) — 评审者 Sprint 合同硬门控
v3.6.2 引入了 Schema 13 sprint 合同和硬门控编排,强制评审者在阅读论文之前预先提交其评分计划。仅限评审者的首个测试案例;写作/评估角色推迟至 v3.6.4。参见 CHANGELOG。
- Schema 13 sprint 合同,包含
panel_size、acceptance_dimensions、failure_conditions(带有severity优先级 + 评审组内cross_reviewer_quantifier)、measurement_procedure、可选的override_ladder、受限的agent_amendments。验证脚本:scripts/check_sprint_contract.py。 - 两次调用的硬门控。 评审者运行论文内容盲评估阶段 1 + 论文可见阶段 2;阶段 1 的输出包裹在
<phase1_output>...</phase1_output>数据定界符中,以缩小自我注入的攻击面。 - 合成器三步机械协议。 构建跨评审者矩阵 → 使用评审组内量词和公认表达词汇评估每个
failure_condition→ 按severity解析优先级。禁止操作列表在editorial_synthesizer_agent中明确列出。 - 提供了两个评审者模板(
shared/contracts/reviewer/full.json面板 5;shared/contracts/reviewer/methodology_focus.json面板 2)。reviewer_re_review、reviewer_calibration、reviewer_guided在 schema 枚举中保留,但在 v3.6.2 中不附带合同模板;它们保留 v3.6.2 之前的行为。reviewer_quick完全从枚举中排除。 academic-paper-reviewerSKILL 版本:1.8.1 → 1.9.0。academic-pipelineSKILL 版本:3.5.1 → 3.6.2(套件版本不变)。套件版本升至3.6.2。- 参见规范
docs/design/2026-04-23-ars-v3.6.2-sprint-contract-design.md和协议academic-paper-reviewer/references/sprint_contract_protocol.md。
v3.5.1 (2026-04-22) — 可选苏格拉底阅读检查探针
v3.5.1 为苏格拉底导师(Socratic Mentor)添加了一个可选诚实性探针(ARS_SOCRATIC_READING_PROBE=1)。默认关闭。参见 CHANGELOG。
- 可选阅读检查探针:当设置
ARS_SOCRATIC_READING_PROBE=1时,苏格拉底导师会在目标导向的会话(用户引用了特定论文)中触发一次性的诚实性探针。拒绝会在不处罚的情况下记录。结果会流入研究计划摘要和阶段 6 的 AI 自我反思报告。无新增 agent,无 schema 变更。 deep-researchSKILL 版本:2.9.0 → 2.9.1。academic-pipelineSKILL 版本:3.5.0 → 3.5.1。套件版本升至3.5.1。
v3.5.0 (2026-04-21) — 协作深度观察者
- 新增 agent:
academic-pipeline中的collaboration_depth_agent(Agent 团队从 3 增至 4)。在每次 FULL/SLIM checkpoint 以及流水线完成时被调用;根据 4 维评分标准评估用户与 AI 的协作。仅提供建议 —— 从不阻止进度。 MANDATORY checkpoint(阶段 2.5 / 4.5 完整性门控)不会调用该观察者。 - 新的评分标准:
shared/collaboration_depth_rubric.mdv1.0。维度:委托强度(Delegation Intensity)、认知警觉度(Cognitive Vigilance)、认知再分配(Cognitive Reallocation)、区域分类(Zone 1 / Zone 2 / Zone 3)。基于 Wang, S., 与 Zhang, H. (2026)。“Pedagogical partnerships with generative AI in higher education: how dual cognitive pathways paradoxically enable transformative learning.” International Journal of Educational Technology in Higher Education, 23:11。DOI 10.1186/s41239-026-00585-x。 - 跨模型分歧会被标记,而非取平均:当设置了
ARS_CROSS_MODEL时,观察者会在两个模型上运行;维度分歧超过 2 分会被报告,而非默默平滑。ARS_CROSS_MODEL_SAMPLE_INTERVAL逃生口用于成本权衡。 - 短阶段防护:用户轮次少于 5 次的阶段会注入静态
insufficient_evidence块,而非调度完整模型观察者。 - 反谄媚纪律:得分 ≥ 7 需要特定的对话轮次引用;区域 3 会触发重新审核;无激励性框架。
academic-pipelineSKILL 版本:3.3.0 → 3.4.0。套件版本升至3.5.0。新增 lint 脚本scripts/check_collaboration_depth_rubric.py+ 10 个测试。
v3.4.0 (2026-04-20) — 合规性 Agent + Schema 12
- 合规性 Agent(共享):单个模式感知 agent,运行 17 项 PRISMA-trAIce 条目(仅系统综述模式)+ 4 项 RAISE 原则 + 8 角色矩阵。挂钩现有的阶段 2.5 / 4.5 完整性门控;基于层级阻止(强制 → 阻止,高影响 → 警告,只读 → 信息)。非系统综述条目仅运行原则部分,仅警告。
- Schema 12 compliance_report 通过
compliance_history[](仅追加)追加到 Material Passport。 - 3 轮用户覆盖梯子会自动将
disclosure_addendum注入手稿。不可能绕过检测。 - 带透明报告的校准,无硬性 FNR/FPR 门控 —— 与
task_type: open-ended自洽。 - 上游新鲜度 CI 会警告 PRISMA-trAIce 漂移(非阻塞)。
- 长时间运行会话文档:Material Passport 作为跨会话恢复机制。
v3.3.6 (2026-04-15) — README 精简 + ARCHITECTURE 文档
- 新增
docs/ARCHITECTURE.md作为流水线结构的单一事实来源(流程、矩阵、数据访问、依赖图、质量门控、模式)。通过 PR #18 合并到主分支。 - 新增
docs/SETUP.md(先决条件、API 密钥、Pandoc/tectonic、跨模型验证、安装方法)和docs/PERFORMANCE.md(token 预算、推荐的 Claude Code 设置)。README 链接到这两个文件,而非内联它们。 - 精简了 README:移除了 ASCII 流水线图和 16 点关键特性列表(已被 ARCHITECTURE.md 取代);技能详情部分现在锚定版本号,并引导读者到 ARCHITECTURE.md 第 3 节查看每个 agent 的成员名单。
- 注意:未对任何技能进行功能更改。纯粹是文档重组。套件版本升至
3.3.6。
v3.3.5 (2026-04-15)
- 添加了
benchmark_report.schema.json+repro_lock可选块到 Material Passport。两者都附带了模式文档、lint 规则和示例。首个正式的 Python 开发依赖清单(requirements-dev.txt)。
v3.3.4 (2026-04-15) — README Changelog Sync Patch
- 同步了
README.md和README.zh-TW.md中的嵌入更新日志部分,使其包含缺失的v3.3.3和v3.3.2版本摘要。 - 扩展了
scripts/check_spec_consistency.py,使得未来 README 更新日志的偏差会导致 CI 失败。
v3.3.3 (2026-04-15) — Release Prep + Lint Hardening
- 强化了 SKILL frontmatter lint 检查:缺失闭合
---分隔符现在会明确失败,而不会被视为有效 YAML 进行解析。 - 解析为有效 YAML 但不是映射的前置元数据现在会报告可读错误,而不会崩溃。
- 修复了两个 README 中发布后审计报告的展示链接损坏问题。
- 在规范一致性检查中增加了 README 相对链接验证,从而让失效链接导致 CI 失败。
- 统一了所有文档中的 DOCX 输出契约:直接生成
.docx依赖于 Pandoc,以 Markdown 加转换说明作为后备方案。 - 准备了
v3.3.3版本:套件版本升级,academic-paper-> v3.0.2,academic-pipeline-> v3.2.2。
v3.3.2 (2026-04-15) — Data Access Levels + Task Type Metadata
- 为所有顶级
SKILL.md文件添加了metadata.data_access_level,并强制使用词汇表:raw,redacted,verified_only。 - 为所有顶级
SKILL.md文件添加了metadata.task_type,并强制使用词汇表:open-ended,outcome-gradable。 - 为这两个元数据字段添加了 lint 脚本和单元测试,并接入到 GitHub Actions 规范一致性工作流中。
- 添加了
shared/ground_truth_isolation_pattern.md,并从shared/handoff_schemas.md链接了新的词汇表。
v3.3.1 (2026-04-14) — Spec Consistency Patch
- 同步了 README、
.claude/CLAUDE.md、MODE_REGISTRY.md和SKILL.md文件,以匹配当前的模式数量和已发布的技能版本。 - 修正了跨模型表述:完整性样本检查和独立的 DA 评审目前已实现;第六审稿人同行评审仍处于计划阶段。
- 澄清了自适应检查点的语义,使得 SLIM 检查点仍然等待用户的显式确认。
- 重申了阶段 2.5 和阶段 4.5 的完整性门禁不可跳过。
- 添加了轻量级的规范一致性检查和 GitHub Actions 工作流,以捕获未来的偏差。
v3.3 (2026-04-09) — PaperOrchestra-Inspired Enhancements
集成了来自 PaperOrchestra (Song, Song, Pfister & Yoon, 2026, Google) 的技术。
- Semantic Scholar API Verification — 通过 S2 API 进行 0 级程序化参考文献存在性检查。Levenshtein >= 0.70 标题匹配、DOI 不匹配检测、通过 S2 ID 进行参考文献去重。如果 API 不可用,则优雅降级。
- Anti-Leakage Protocol — 知识隔离指令优先使用会话材料而非 LLM 参数记忆。对缺失内容标记
[MATERIAL GAP],而不是从记忆中填充。降低模式 5/6 失败风险。 - VLM Figure Verification (可选) — 使用具有视觉能力的 LLM 对渲染图形进行闭环验证。10 点检查清单,最多 2 次细化迭代。
- Score Trajectory Protocol — 跨修订轮次追踪每个维度评分表的分差(7 个维度)。检测回退(分差 < -3)并触发强制检查点。
- Stage 2 Parallelization — 在提纲完成后,可视化和论证构建可以并行运行。
- 新版本:deep-research v2.8, academic-paper v3.0, academic-pipeline v3.2
v3.2 (2026-04-09) — Lu 2026 Nature Integration
集成了来自 Lu et al. (2026, Nature 651:914-919) 的见解——首个通过盲审的全自主 AI 研究系统。
- 7-mode AI Research Failure Mode Checklist — 在阶段 2.5/4.5 阻止流程,针对疑似实现错误、幻觉结果、捷径依赖、错误视为洞察、方法捏造、框架锁定等问题。扩展了现有的 5 种引用幻觉分类。
- Reviewer Calibration Mode (academic-paper-reviewer v1.8) — 可选功能,根据用户提供的金标准集衡量假阴性率/假阳性率/平衡准确率。5 倍集成,跨模型默认开启,会话范围内的置信度披露。
- Disclosure Mode (academic-paper v2.9) — 特定会议/期刊的 AI 使用声明生成器。v1 涵盖 ICLR, NeurIPS, Nature, Science, ACL, EMNLP。
- Early-Stopping Criterion (academic-pipeline v3.1) — 在流程开始时进行收敛检查 + 预算透明化。
- Fidelity-Originality Mode Spectrum — 根据 Lu 2026 图 1c 对所有 3 项技能的模式进行分类。
- 新版本:academic-paper v2.9, academic-paper-reviewer v1.8, academic-pipeline v3.1
v3.1.1 (2026-04-09) — IS Senior Scholars’ Basket of 11
外部贡献:@mchesbro1 最初提出并起草了 IS 8 种期刊篮(Issue #5);@cloudenochcsis 将其扩展为完整的 Senior Scholars’ Basket of 11(Issue #7,PR #8)。更新了 academic-paper-reviewer/references/top_journals_by_field.md 的第 7 节,添加了 Decision Support Systems、Information & Management 以及 Information and Organization。来源:AIS Senior Scholars’ List of Premier Journals。
v3.1 (2026-04-06) — Anti-Context-Rot + Cognitive Frameworks + Lean Size
灵感来源于 aspi6246/Claude-Code-Skills-for-Academics 的模式。
Wave 1: Anti-Context-Rot Anchors
- 在所有 4 项技能中明确列出了 29 条反模式(每项技能 7-8 条,表格格式,包含“失败原因”和“正确行为”)
- 在关键规则上标记了 22 条 IRON RULE,即使长时间对话也不得违反
- 对 academic-paper-reviewer 施加只读约束(审稿人不能修改稿件)
Wave 2: Traceability + Cognitive Frameworks + Reinforcement
- R&R 可追溯性矩阵(Schema 11):在重新审阅输出中添加“作者声称”和“已验证?”列,实现对修订声明的独立验证
- 3 个认知框架参考文件,教导智能体“如何思考”而不仅仅是“做什么”:
argumentation_reasoning_framework.md— 图尔敏模型、Bradford Hill 因果推理、最佳解释推理、认识状态分类review_quality_thinking.md— 三个视角(内部效度、外部效度、贡献),常见审稿人陷阱,校准问题writing_judgment_framework.md— 清晰度测试、读者旅程、学科特定语气、修订决策矩阵
- 对话中强化协议:在每个流程转换处发送阶段特定的 IRON RULE + 反模式提醒
- 在每个 FULL 检查点进行自我检查问题(引用完整性、谄媚让步、质量轨迹、范围纪律、完整性)
Wave 3:精简技能规模
- SKILL.md 总大小从 142KB 缩减至 85KB(−40%),方法是将详细协议提取到
references/文件中 - 新增约 15 个参考文件(重新评审协议、引导模式、系统性评审、流程总结、外部评审等)
- 所有 IRON RULE 标记保留在 SKILL.md 中;详细内容按需加载
- 新版本:deep-research v2.7、academic-paper v2.8、academic-paper-reviewer v1.7、academic-pipeline v3.0
v3.0(2026-04-03)——反谄媚 + 意图检测 + 对话健康度
- 魔鬼代言人让步阈值(deep-research + academic-paper-reviewer):DA 必须在回应前对反驳进行 1-5 分评分。只有在 ≥4 分时才允许让步。不允许连续让步。跟踪让步率。每个检查点后检测框架锁定。
- 攻击强度保持(academic-paper-reviewer):DA 在遭遇反击时不会软化。附带明确偏离检测的反驳评估协议。反谄媚规则防止将持续的反击当作有效证据。
- 意图检测层(deep-research socratic):将用户意图分类为探索型或目标导向型。探索型模式禁用自动收敛、提高最大轮数、禁止过早结束。每 3 轮重新评估。
- 对话健康度指标(deep-research socratic):每 5 轮静默自检,检查持续同意、冲突回避、过早收敛。检测到同意模式时自动注入挑战。
- 跨模型验证协议(共享,可选):使用 GPT-5.4 Pro 或 Gemini 3.1 Pro 对完整性验证样本进行交叉检查,并独立进行 DA 批判。第六评审人同行评审仍处于计划阶段,尚未实现。通过设置
ARS_CROSS_MODEL环境变量激活——未设置时一切照常运行。完整设置指南、API 模式及成本估算见shared/cross_model_verification.md。 - AI 自我反思报告(academic-pipeline 阶段 6):流水线后对 AI 行为模式的自我评估——DA 让步率、检查点跳过率、健康警报、谄媚风险等级(低/中/高)、框架锁定事件、收敛模式分析。包含讽刺性说明:“此自我反思本身由可能具有谄媚行为的同一 AI 生成。”
- 起源:通过一个 4 轮辩证实验发现,其中 DA 让步过快,苏格拉底导师试图过早收敛,整个辩论始终锁定在人类设定的框架内。
- 版本:deep-research v2.5、academic-paper-reviewer v1.5、academic-pipeline v2.8
v2.9.1(2026-04-03)——技能元数据
- 为所有 4 个 SKILL.md 的前置元数据添加了
status: active和related_skills交叉引用。 - 支持技能发现工具以及跨
deep-research↔academic-paper↔academic-paper-reviewer↔academic-pipeline的技能导航。
v2.9(2026-03-27)——风格校准 + 写作质量检查
- 风格校准(academic-paper 接收步骤 10,可选):提供 3 篇以上过往论文,流水线将学习你的写作风格——句子节奏、词汇偏好、引用整合方式。在草稿阶段作为软性指南应用;学科惯例始终优先。优先级体系:学科规范(硬)> 期刊惯例(强)> 个人风格(软)。详见
shared/style_calibration_protocol.md - 写作质量检查(
academic-paper/references/writing_quality_check.md):在草稿自审期间应用的写作质量检查清单。5 个类别:AI 高频词警告(25 个词)、标点模式控制(em dash ≤3)、清嗓式开头检测、结构模式警告(三法则、均匀段落、同义词循环)以及突发性检查(句子长度变化)。这些是好的写作规则——而非规避检测。 - 风格档案通过 academic-pipeline 的材料护照传递(见
shared/handoff_schemas.md中的架构 10) - deep-research 报告编译器也可选使用这两个功能
- 版本:academic-paper v2.5、deep-research v2.4、academic-pipeline v2.7
v2.8(2026-03-22)——SCR 循环阶段 1:陈述-挑战-反思
- 苏格拉底导师代理(deep-research + academic-paper):SCR(陈述-挑战-反思)协议集成
- 承诺门控:在每一层/章节过渡前出示证据前收集用户预测
- 确定性触发的矛盾:检测高确定性语言(“显然”、“清楚地”)并引入反面观点
- 自适应强度:跟踪承诺准确性,动态调整挑战频率
- 自我校准信号(S5):新的收敛信号,跟踪用户在对话中的自我校准成长
- SCR 开关:用户可以说“跳过预测”来禁用,或说“重新打开预测”在对话中重新启用;苏格拉底提问正常继续
deep-research/references/socratic_questioning_framework.md:SCR 覆盖协议,将 SCR 阶段映射到苏格拉底功能- 新增
CHANGELOG.md
v2.7(2026-03-09)——完整性验证 v2.0:反幻觉重构
- integrity_verification_agent v2.0:反幻觉指令(无需 AI 记忆验证),消除灰色地带分类(仅 VERIFIED/NOT_FOUND/MISMATCH),每项参考文献强制使用 WebSearch 审计轨迹,阶段 4.5 独立重新验证,灰色地带预防规则
- 已知幻觉模式:来自 GPTZero × NeurIPS 2025 研究的 5 类分类(TF/PAC/IH/PH/SH)、5 种复合欺骗模式、真实案例研究、文献统计
- 发表后审计:对所有 68 个参考文献进行完整 WebSearch 验证,发现 21 个问题(31% 错误率)通过了 3 轮完整性检查——证明了外部验证的必要性
- 论文更正:移除 4 个捏造参考文献,修正 6 个作者错误,更正 7 个元数据错误,修复 2 个格式问题
v2.6.2(2026-03-09)——基于意图的模式激活
- deep-research:苏格拉底模式现在使用基于意图的激活而非关键词匹配。可在任何语言中工作——检测含义(例如“用户希望获得引导式思考”)而非匹配特定字符串。
- academic-paper:计划模式现在使用基于意图的激活。检测意图信号,如“用户不确定如何开始”或“用户希望获得逐步指导”,适用于任何语言。
- 两种模式现在都有一个默认规则:当意图不明确时,优先选择
socratic/plan而非full——先引导更安全。 - 两层架构:第 1 层(技能激活)使用双语关键词提高匹配置信度;第 2 层(模式路由)使用与语言无关的意图信号。
v2.6.1(2026-03-09)——双语触发关键词
- deep-research:为通用激活和苏格拉底模式添加了繁体中文触发关键词。
- academic-paper:添加了繁体中文触发关键词和计划模式触发部分。
- 两个模式选择指南现在都包含双语示例和特定于中文的错误选择场景。
v2.6 / v2.4 / v1.4 (2026-03-08) — 15+ 项改进
- deep-research v2.3: 新增系统评价 / PRISMA 模式(第 7 种);3 个新 agent(risk_of_bias、meta_analysis、monitoring);PRISMA 协议/报告模板;苏格拉底式收敛标准(4 个信号 + 自动结束);快速模式选择指南
- academic-paper v2.4: 2 个新 agent(visualization、revision_coach);附带 4 种状态类型的修订追踪模板;引文格式转换(APA ↔ Chicago ↔ MLA ↔ IEEE ↔ Vancouver);统计可视化标准;苏格拉底式收敛标准;修订恢复示例;LaTeX 输出加固 — 强制使用
apa7文档类、文本对齐修复(ragged2e+etoolbox)、表格列宽公式、双语摘要居中、标准化字体栈(Times New Roman + Source Han Serif TC VF + Courier New),仅通过 tectonic 生成 PDF - academic-paper-reviewer v1.4: 质量评分标准,含 0-100 评分与行为指标;决策映射(≥80 接收,65-79 小修,50-64 大修,<50 拒稿);快速模式选择指南
- academic-pipeline v2.6: 自适应检查点系统(FULL/SLIM/MANDATORY);完整性检查中的 E 阶段声明验证;用于中途溯源的材料护照;跨技能模式顾问(14 种场景);团队协作协议;增强型移交模式(9 种模式);完整性故障恢复示例
v2.4 / v1.3 (2026-03-08)
- academic-pipeline v2.4: 新增第 6 阶段“流程总结”——自动生成结构化的论文创建流程记录(MD → LaTeX → PDF,双语);强制性的最后一章:协作质量评估,包含 6 个维度(方向设定、智力贡献、质量把关、迭代纪律、授权效率、元学习)按 1-100 分评分,诚实反馈及改进建议;流水线从 9 个阶段扩展至 10 个阶段
v2.3 / v1.3 (2026-03-08)
- academic-pipeline v2.3: 第 5 阶段“定稿”现提示选择格式样式(APA 7.0 / Chicago / IEEE);PDF 必须通过
tectonic从 LaTeX 编译(无 HTML 转 PDF);APA 7.0 使用apa7文档类(man模式)配合 XeCJK 实现双语 CJK 支持;字体栈:Times New Roman + Source Han Serif TC VF + Courier New
v2.2 / v1.3 (2025-03-05)
- 跨 Agent 质量对齐:在所有 agent 中统一定义(同行评审、时效规则、严重程度 CRITICAL、来源层级)
- deep-research v2.2: 综合反模式、苏格拉底自动结束条件、DOI+WebSearch 验证、增强的伦理完整性检查、模式转换矩阵
- academic-paper v2.2: 4 级论证评分、剽窃筛查、2 条新失败路径(F11 桌面拒稿恢复、F12 会议转期刊)、计划→完整模式转换
- academic-paper-reviewer v1.3: DA 与 R3 角色边界、CRITICAL 级发现标准、共识分类(4/3/SPLIT/DA-CRITICAL)、置信度加权、亚洲及区域期刊参考
- academic-pipeline v2.2: 检查点确认语义、模式切换矩阵、失败回退矩阵、状态所有权协议、材料版本控制
v2.0.1 (2026-03)
- 简化 4 个 SKILL.md(减少 371 行,-16.5%):消除跨技能重复、内联模板→文件引用、冗余路由表、重复的模式选择章节
- 修复 academic-paper 与 academic-pipeline 之间修订循环上限的矛盾
v2.0 (2026-02)
- academic-pipeline v2.0: 5 阶段→9 阶段、强制性完整性验证、两阶段评审、苏格拉底式修订辅导、可重复性保证
- academic-paper-reviewer v1.1: + 魔鬼代言人审稿人(第 7 个 agent)、+ 再审模式(验证)、+ 审后苏格拉底式辅导
- 新 Agent:
integrity_verification_agent— 带有审计追踪的 100% 参考文献/数据验证 - 新 Agent:
devils_advocate_reviewer_agent— 8 维度论文挑战者 - 输出顺序:MD → 可用时通过 Pandoc 生成 DOCX(否则给出说明)→ 询问 LaTeX → 确认 → PDF
v1.0 (2026-02)
- 初始发布
- deep-research v2.0(10 个 agent,6 种模式,包括 socratic)
- academic-paper v2.0(10 个 agent,8 种模式,包括 plan)
- academic-paper-reviewer v1.0(6 个 agent,4 种模式,包括 guided)
- academic-pipeline v1.0(编排器)